
El aprendizaje automático directamente en el dispositivo posee el potencial de revolucionar innumerables productos, ya sea la categorización de objetos de un sensor de imagen, gestos de un acelerómetro o frases de un flujo de audio. Sin embargo, para lograr esto, hay que ejecutar los algoritmos en los componentes embebidos. El desarrollo de aplicaciones basadas en el aprendizaje automático requiere la gestión de múltiples disciplinas técnicas, pero muchas empresas sólo tienen algunas de estas disciplinas representadas internamente.
Aprendizaje
Por ello, los científicos de datos, los ingenieros de aprendizaje automático y los desarrolladores de software son contratados para desarrollar, capacitar, ajustar y probar modelos para el aprendizaje automático. Aquí, el problema radica en que estos modelos no se suelen ejecutar en el hardware embebido o los dispositivos móviles porque la mayoría de los ingenieros de aprendizaje automático no han usado nunca modelos en hardware integrado y no están familiarizados con las limitaciones de recursos. Para que los modelos entrenados puedan utilizarse en SoC, FPGA y microprocesadores móviles, el modelo debe optimizarse y cuantificarse.
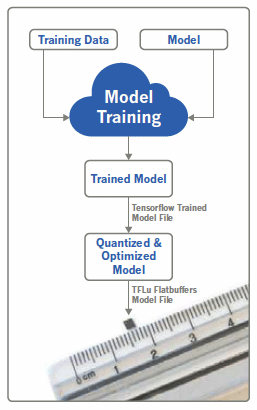
modelos deben cuantificarse y optimizarse.
Los fabricantes de semiconductores, por su parte, se enfrentan al reto de desarrollar productos que satisfagan nuevos requisitos en lo que se refiere al rendimiento, el coste y el formato—todo ello con estrictas demandas de tiempo de llegada al mercado. Se requiere flexibilidad para las interfaces, las entradas, las salidas y el uso de la memoria para que los productos puedan adaptarse a una amplia variedad de aplicaciones.
TensorFlow Lite simplifica la optimización y la cuantización
Esto se ha vuelto algo más fácil en los últimos años gracias a TensorFlow Lite de Google, una plataforma de código abierto para aprendizaje automático que ahora incluye scripts que se pueden usar para optimizar y cuantificar los modelos de aprendizaje automático en un archivo “FlatBuffers”(*.tflite). Utiliza parámetros configurados para un determinado entorno de aplicación.
En el mejor de los casos, un producto de hardware embebido debería poder importar archivos FlatBuffer directamente desde TensorFlow, sin tener que usar métodos de optimización propios o específicos de hardware fuera del ecosistema de TensorFlow. Esto permite a los ingenieros de software y hardware utilizar fácilmente el archivo FlatBuffer cuantificado y optimizado en FPGA, SoC y microcontroladores.
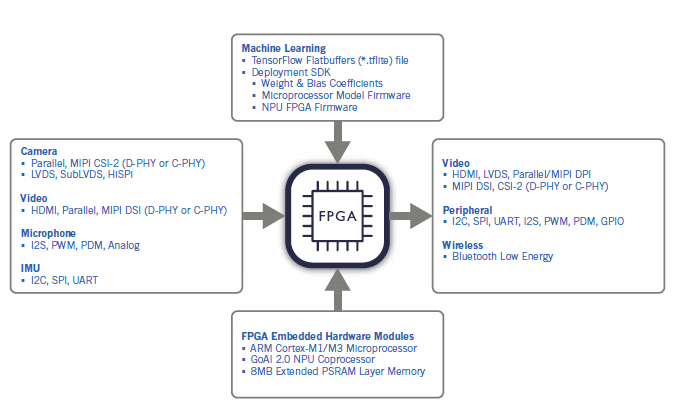
Una comparación de SoC, MCU y FPGA
Las plataformas de hardware embebidas sólo tienen recursos limitados, no son especialmente buenas para fines de desarrollo y resultan complicadas de usar. Pero, a cambio, ofrecen mínimo consumo de energía, bajos costes y módulos con pequeñas dimensiones. ¿Qué aportan los SoC, los microcontroladores y los FPGA?
Los SoC proporcionan el máximo rendimiento y muchas interfaces estándares, pero también suelen tener el mayor consumo de energía. Las entradas y las salidas específicas de la interfaz consumen mucho espacio en el chip, lo que hace que sean relativamente costosos.
La ventaja de los microcontroladores consiste en su mínimo consumo de energía y pequeño formato. Sin embargo, a veces, están limitados en lo que se refiere a rendimiento de aprendizaje automático y capacidad de modelado. Los modelos de gama alta de estos productos sólo suelen ofrecer interfaces especializadas, como aquellas para cámaras o micrófonos digitales.
Los FPGA cubren un amplio segmento entre los microcontroladores y los SoC. Se encuentran disponibles con una gran selección de encapsulados y entradas y salidas flexibles. Esto permite que soporten cualquier interfaz requerida para una aplicación dada sin tener que “desaprovechar” espacio de chip. Las opciones de configuración también pueden adecuar el coste y el consumo de energía con el rendimiento e integrar funciones adicionales. El problema con el uso de los FPGA en aplicaciones de aprendizaje automático es la ausencia de soporte e integración para las plataformas SDK, como TensorFlow Lite.
FPGA de aprendizaje automático
Para superar este “defecto”, Gowin Semiconductor proporciona un SDK en su plataforma GoAI 2.0 que extrapola modelos y coeficientes, genera código C para el procesador ARM Cortex-M integrado y produce flujos de bits y firmware para los FPGA.
Otro desafío se encuentra en la importancia de los requisitos de memoria flash y RAM de los modelos de aprendizaje automático. Los nuevos FPGA µSoC híbridos, como el Gowin GW1NSR4P, satisfacen las necesidades de integrar de 4 a 8 MB de PSRAM adicional. El GW1NSR4P ofrece un coprocesador GoAI 2.0 especial para las tareas de procesamiento y almacenamiento acelerados de las capas plegables y agrupadas. Se utiliza junto con su núcleo IP Cortex-M de hardware, que controla los parámetros de capa, el procesamiento del modelo y los resultados de salida.
Muchos proveedores de semiconductores programables también suministran programas y servicios de diseño para una curva de aprendizaje más pronunciada a aquellos clientes que utilizan hardware embebido para aprendizaje automático. Gowin no una excepción aquí—el programa de servicio de diseño GoAI ayuda a los usuarios a buscar una solución de un solo chip por categoría u obtener asistencia con la implementación de modelos entrenados y probados «listos para usar», pero que no saben cómo deben comunicarse con el hardware integrado.
Los fabricantes ofrecen este tipo de programas para ayudar a las empresas a utilizar menos recursos en lo que se refiere al aprendizaje automático embebido y en las implementaciones de hardware integrado (TinyML), por lo que se pueden concentrar más activamente en el desarrollo de su producto.
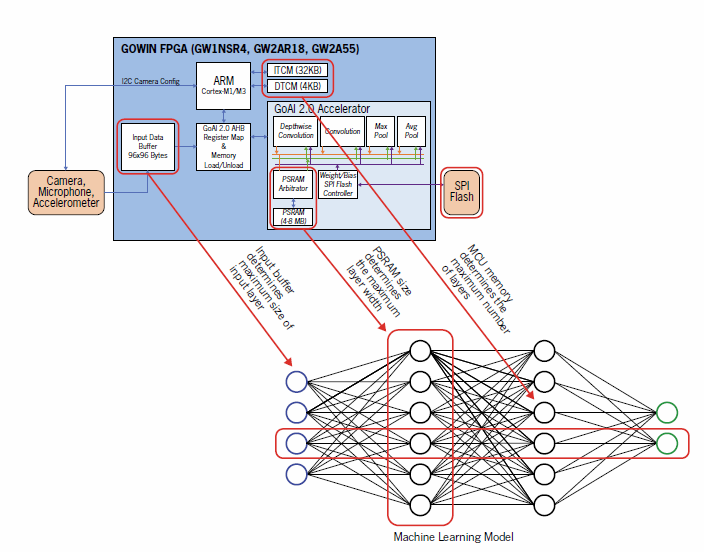
y un almacenamiento acelerados de las capas plegables y agrupadas.
Conclusión
El aprendizaje automático embebido y local actualmente es un campo popular y en constante crecimiento para muchos desarrolladores de productos. No obstante, existen unos desafíos considerables, ya que se necesita contar con ingenieros de una gran variedad de disciplinas y campos para poder desarrollar estas soluciones. Algunos fabricantes de semiconductores programables responden a esta necesidad mediante el uso de herramientas de ecosistema populares para hardware embebido y la oferta de dispositivos con interfaces flexibles, memoria extendida, nuevas herramientas de software y servicios de diseño.
Para permitir que el aprendizaje automático se ejecute en hardware integrado, los modelos deben cuantificarse y optimizarse.
Los FPGA ofrecen la interfaz adecuada y facilidad de escalabilidad para cada aplicación.
Con PSRAM adicional, el GW1NSR4P de Gowin proporciona la máxima amplitud de capa y, por lo tanto, permite un procesamiento y un almacenamiento acelerados de las capas plegables y agrupadas.
Autores: Zibo Su, Product Manager Digital de Rutronik, y Daniel Fisher, Senior FAE EMEA de GoWin –Semiconductor




