La democratización de la IA plantea nuevos retos para los diseñadores de sistemas embebidos
Yann LeFaou analiza cómo la democratización de la IA plantea nuevos retos para los diseñadores de sistemas embebidos que buscan crear aplicaciones de «ML en el Edge» que funcionen con eficacia y, al mismo tiempo, cumplan los requisitos mínimos de procesador y almacenamiento y las exigencias de consumo energético más bajas posibles de los dispositivos IoT.
Desde la vigilancia y el control de acceso hasta las fábricas inteligentes y el mantenimiento predictivo, el despliegue de la inteligencia artificial (IA) basada en modelos de aprendizaje automático (ML) se está generalizando en las aplicaciones industriales de procesamiento edge del IoT. Con esta omnipresencia, la creación de soluciones basadas en la IA se ha «democratizado», pasando de ser una disciplina especializada de los científicos de datos a algo que se espera que comprendan los diseñadores de sistemas embebidos. El reto de esta democratización es que los diseñadores no siempre están bien preparados para definir el problema que hay que resolver y para capturar y organizar los datos de la forma más adecuada. Además, a diferencia de las soluciones para consumidores, existen pocos conjuntos de datos para implementaciones de IA industrial, lo que significa que a menudo hay que crearlos desde cero, a partir de los propios datos del usuario.
Hacia la generalización
La IA se ha generalizado, y el aprendizaje profundo y el aprendizaje automático (DL y ML, respectivamente) están detrás de muchas aplicaciones que ahora damos por sentadas, como el procesamiento del lenguaje natural, la visión por ordenador, el mantenimiento predictivo y la minería de datos. Las primeras implementaciones de la IA se basaban en la nube o en servidores, lo que requería una gran capacidad de procesamiento y almacenamiento, así como un alto ancho de banda entre la aplicación de IA/ML y el edge (punto final). Y aunque estas configuraciones siguen siendo necesarias para aplicaciones de IA generativa como ChatGPT, DALL-E y Bard, en los últimos años ha aparecido la IA procesada en el edge, en la que los datos se procesan en tiempo real en el punto de captura. El procesamiento en el edge reduce en gran medida la dependencia de la nube, agiliza el sistema/la aplicación en su conjunto, requiere menos energía, y es más económico. Muchos también consideran que la seguridad ha mejorado, pero quizá sea más preciso decir que el principal objetivo de seguridad ha pasado de proteger las comunicaciones en tránsito entre la nube y el punto final a hacer más seguros los dispositivos edge.
La IA/ML en el edge se puede implementar en un sistema embebido tradicional, para el que los diseñadores tienen acceso a potentes microprocesadores, unidades de procesamiento gráfico y una gran cantidad de dispositivos de memoria, recursos similares a los de un PC. Sin embargo, existe una creciente demanda de dispositivos IoT (comerciales e industriales) que incorporen IA/ML en el edge y que, por lo general, tienen recursos de hardware limitados y, en muchos casos, funcionan con baterías.
El potencial de la IA/ML en el edge que se ejecuta en hardware con recursos y potencia limitados ha dado lugar al término TinyML. Existen ejemplos de uso en la industria (por ejemplo, para el mantenimiento predictivo), la automatización de edificios (monitorización medioambiental), la construcción (supervisión de la seguridad del personal) y la seguridad.
El flujo de datos
La IA (y, por extensión, su subconjunto ML) requiere un flujo de trabajo que va desde la captura/recopilación de datos hasta la implementación del modelo (Figura 1). En lo que respecta a TinyML, la optimización en todas las etapas del flujo de trabajo es esencial debido a los recursos limitados del sistema embebido.
Por ejemplo, los requisitos de recursos de TinyML se consideran una velocidad de procesamiento de 1 a 400 MHz, 2 a 512 KB de RAM y 32 KB a 2 MB de almacenamiento (Flash). Además, con 150 µW a 23,5 mW, operar con un presupuesto energético tan reducido suele resultar complicado.
Figura 1. arriba, un flujo de trabajo de IA simplificado. No se muestra, pero la implementación del modelo debe retroalimentar el flujo con datos, lo que puede influir incluso en la recopilación de datos.
Además, hay una consideración más importante, o más bien una compensación, cuando se trata de integrar la IA en un sistema embebido con recursos limitados. Los modelos son cruciales para el comportamiento del sistema, pero los diseñadores a menudo se ven obligados a hacer concesiones entre la calidad/precisión del modelo, que influye en la fiabilidad/seguridad del sistema, y el rendimiento, principalmente la velocidad de funcionamiento y el consumo de energía.
Otro factor clave es decidir qué tipo de IA/ML se va a emplear. En general, se pueden utilizar tres tipos de algoritmos: supervisados, no supervisados y reforzados.
Soluciones
Incluso los diseñadores con un buen conocimiento de la IA y el ML pueden tener dificultades para optimizar cada etapa del flujo de trabajo de IA/ML y lograr el equilibrio perfecto entre la precisión del modelo y el rendimiento del sistema. Entonces, ¿cómo pueden abordar estos retos los diseñadores embebidos sin experiencia previa?
En primer lugar, es importante no perder de vista el hecho de que los modelos implementados en dispositivos IoT con recursos limitados serán eficientes si el modelo es pequeño y la tarea de IA se limita a resolver un problema sencillo.
Afortunadamente, la llegada del ML (y en particular del TinyML) al ámbito de los sistemas embebidos ha dado lugar a nuevos (o mejorados) entornos de desarrollo integrado (IDE), herramientas de software, arquitecturas y modelos, muchos de los cuales son de código abierto. Por ejemplo, TensorFlow™ Lite para microcontroladores (TF Lite Micro) es una biblioteca de software gratuita y de código abierto para ML e IA. Ha sido diseñada para implementar ML en dispositivos con solo unos pocos KB de memoria. Además, los programas se pueden escribir en Python, que también es de código abierto y gratuito.
En cuanto a los IDE, MPLAB® X de Microchip es un ejemplo de este tipo de entorno. Este IDE se puede utilizar con MPLAB ML de la empresa, un complemento de MPLAB X desarrollado especialmente para crear código optimizado de reconocimiento de sensores de IA IoT. Con tecnología AutoML, MPLAB ML automatiza completamente cada paso del flujo de trabajo de IA ML, eliminando la necesidad de crear modelos repetitivos, tediosos y que requieren mucho tiempo. La extracción de características, el entrenamiento, la validación y las pruebas garantizan modelos optimizados que satisfacen las restricciones de memoria de los microcontroladores y microprocesadores, lo que permite a los desarrolladores crear y desplegar rápidamente soluciones ML en MCUs o MPUs de 32 bits basados en Arm® Cortex de Microchip.
En el flujo
Las tareas de optimización del flujo de trabajo se pueden simplificar comenzando con conjuntos de datos y modelos ya disponibles. Por ejemplo, si un dispositivo IoT habilitado para ML necesita reconocimiento de imágenes, tiene sentido comenzar con un conjunto de datos existente de imágenes estáticas y videoclips etiquetados para el entrenamiento del modelo (pruebas y evaluación), teniendo en cuenta que se requieren datos etiquetados para los algoritmos de ML supervisados.
Ya existen muchos conjuntos de datos de imágenes para aplicaciones de visión por ordenador. Sin embargo, como están pensados para aplicaciones basadas en PC, servidores o la nube, suelen ser de gran tamaño. ImageNet, por ejemplo, contiene más de 14 millones de imágenes anotadas.
Dependiendo de la aplicación de ML, es posible que solo se necesiten unos pocos subconjuntos; por ejemplo, muchas imágenes de personas, pero solo unas pocas de objetos inanimados. Por ejemplo, si se van a utilizar cámaras con ML en una obra, podrían dar la alarma inmediatamente si una persona que no lleva casco entra en su campo de visión. El modelo de ML tendrá que entrenarse, pero es posible que solo se necesiten unas pocas imágenes de personas con o sin casco. Sin embargo, es posible que se necesite un conjunto de datos más grande para los tipos de cascos y un rango suficiente dentro del conjunto de datos para tener en cuenta diversos factores, como las diferentes condiciones de iluminación.
Disponer de las entradas (datos) en tiempo real y el conjunto de datos correctos, preparar los datos y entrenar el modelo corresponden a los pasos 1 a 3 de la figura 1. La optimización del modelo (paso 4) suele consistir en la compresión, que ayuda a reducir los requisitos de memoria (RAM durante el procesamiento y NVM para el almacenamiento) y la latencia del procesamiento.
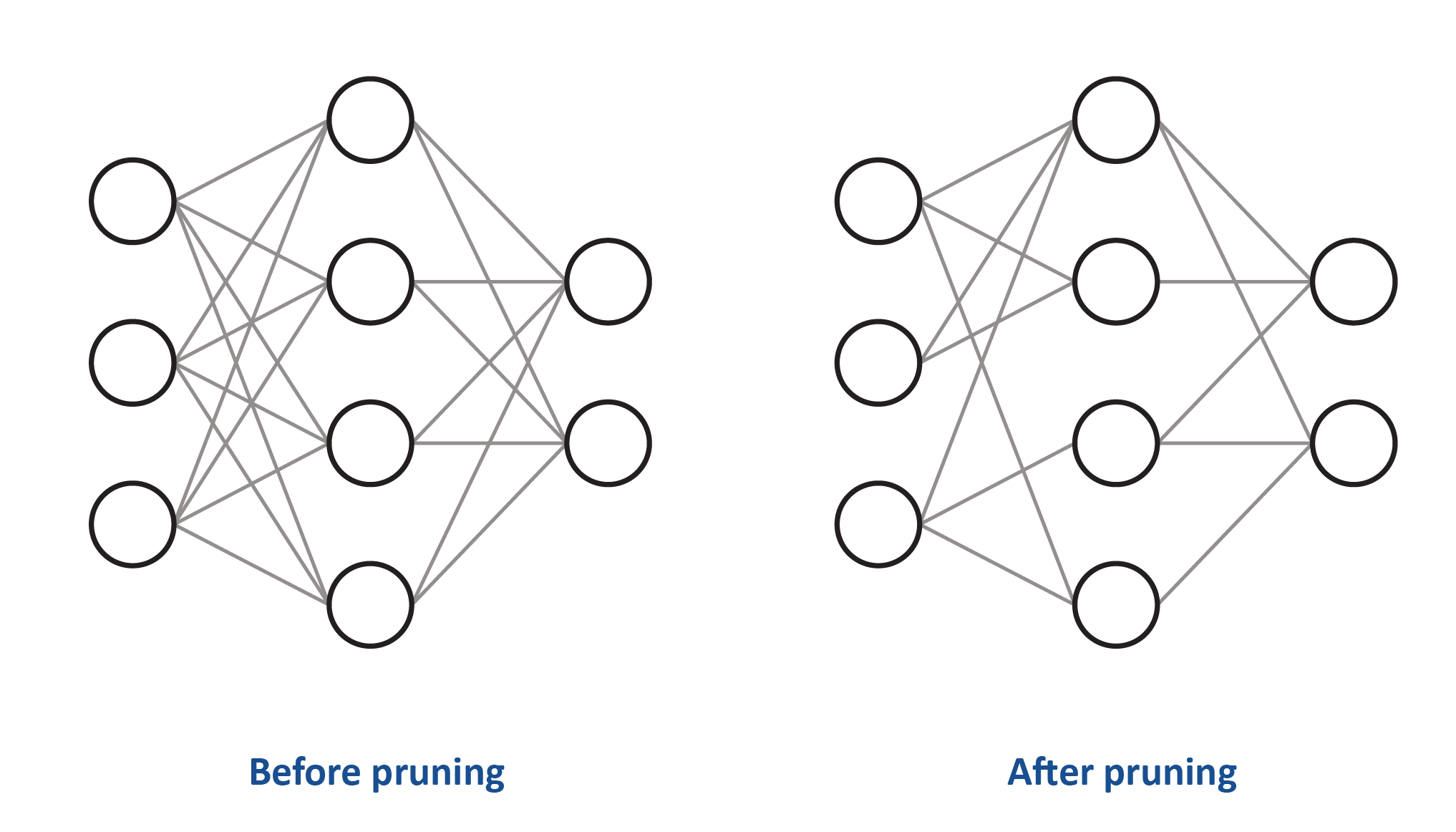
En cuanto al procesamiento, muchos algoritmos de IA, como las redes neuronales convolucionales (CNN), tienen dificultades con los modelos complejos. Una técnica de compresión muy utilizada es el «pruning» o depuración (véase la figura 2), de la que existen cuatro tipos: depuración de pesos, de unidades/neuronas y depuración iterativa.
Figura 2. El pruning reduce la densidad de la red neuronal. Arriba, el peso de algunas de las conexiones entre las neuronas se ha establecido en cero. No se muestra, pero a veces también se pueden depurar las neuronas
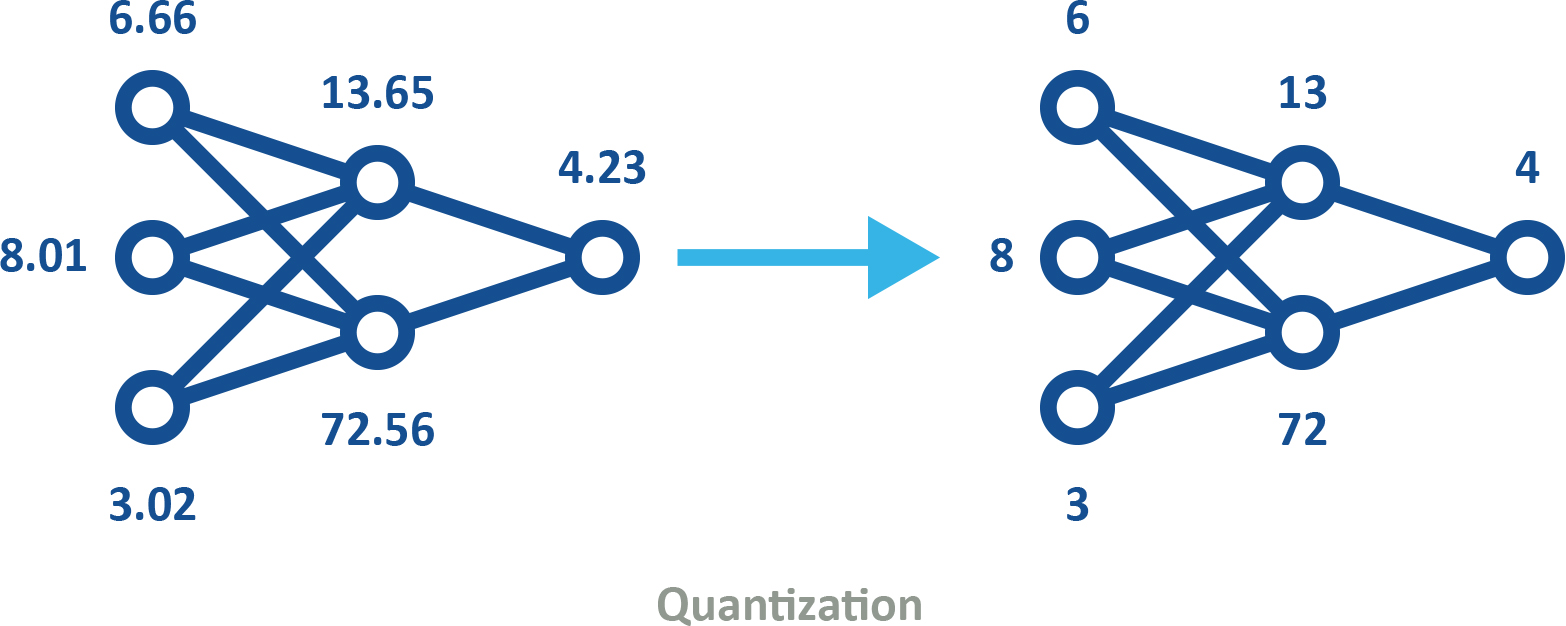
La cuantificación («quantization») es otra técnica de compresión muy utilizada. Se trata del proceso de convertir datos en un formato de alta precisión, como el de punto flotante de 32 bits (FP32), a un formato de menor precisión, por ejemplo, un entero de 8 bits (INT8). El uso de modelos cuantificados (véase la figura 3) puede incorporarse al entrenamiento de las máquinas de dos maneras.
La cuantificación posterior al entrenamiento implica el uso de modelos en, por ejemplo, formato FP32 y, cuando se considera que el entrenamiento ha finalizado, la cuantificación para su implementación. Por ejemplo, se puede utilizar TensorFlow estándar para el entrenamiento y la optimización iniciales del modelo en un PC. A continuación, el modelo se puede cuantificar y, a través de TensorFlow Lite, integrarse en el dispositivo IoT.
El entrenamiento con cuantificación emula la cuantificación en tiempo de inferencia, creando un modelo que las herramientas posteriores utilizarán para producir modelos cuantificados.
Figura 3. Los modelos cuantificados utilizan una precisión menor, lo que reduce los requisitos de memoria y almacenamiento y mejora la eficiencia energética, al tiempo que conservan la misma forma.
Aunque la cuantificación es útil, no debe utilizarse en exceso, ya que puede ser análoga a la compresión de una imagen digital mediante la representación de los colores con menos bits y/o utilizando menos píxeles, es decir, llegará un punto en el que la imagen será difícil de interpretar.
Resumen
Como mencionamos al principio, la IA está ahora plenamente integrada en el ámbito de los sistemas embebidos. Sin embargo, esta democratización significa que los ingenieros de diseño que antes no necesitaban comprender la IA y el ML se enfrentan ahora al reto de implementar soluciones basadas en la IA en sus diseños.
Aunque el reto de crear aplicaciones de ML aprovechando al máximo los limitados recursos de hardware puede resultar abrumador, no es nuevo, al menos no para los diseñadores de sistemas embebidos con experiencia. La buena noticia es que existe una gran cantidad de información (y formación) disponible en la comunidad de ingenieros, así como IDE como MPLAB X, creadores de modelos como MPLAB ML y conjuntos de datos y modelos de código abierto. Este ecosistema ayuda a los ingenieros con diferentes niveles de conocimientos a acelerar las soluciones de IA y ML, que ahora pueden implementarse en microcontroladores de 16 bits e incluso de 8 bits.
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu Proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.