
Autor: Kavita Char, Produktmarketingmanagerin
Das Internet der Dinge explodiert. Geräte sind dank allgegenwärtiger kabelgebundener und kabelloser Konnektivität miteinander verbunden und kommunizieren miteinander. Diese Hyperkonnektivität ermöglicht die Sammlung riesiger Datenmengen, die gesammelt, analysiert und für intelligente Entscheidungen genutzt werden können. Die Fähigkeit, Erkenntnisse aus Daten zu gewinnen und auf der Grundlage dieser Erkenntnisse autonome Entscheidungen zu treffen, ist die Essenz der Künstlichen Intelligenz (KI). Die Kombination von KI und IoT oder künstlicher Intelligenz der Dinge (AIoT) ermöglicht die Schaffung „intelligenter“ Geräte, die aus Daten lernen und Entscheidungen ohne menschliches Eingreifen treffen.
Es gibt mehrere Treiber für diesen Trend zur Entwicklung von Intelligenz in Edge-Geräten:
- Die Entscheidungsfindung am Edge reduziert die mit der Cloud-Konnektivität verbundenen Latenz und Kosten und ermöglicht einen Echtzeitbetrieb
- Mangelnde Bandbreite bei Cloud-Verbindungen fördert die Datenverarbeitung und Entscheidungsfindung auf Edge-Geräten.
- Sicherheit ist ein zentraler Aspekt: Datenschutz- und Vertraulichkeitsanforderungen machen es erforderlich, Daten auf dem Gerät selbst zu verarbeiten und zu speichern.
Daher bietet AI at the Edge Vorteile wie Autonomie, geringere Latenz, geringeren Stromverbrauch, geringere Bandbreitenanforderungen, geringere Kosten und höhere Sicherheit, was sie allesamt attraktiver für neue Anwendungen und neue Anwendungsfälle macht.
AIoT hat neue Märkte für MCUs eröffnet und ermöglicht eine zunehmende Anzahl neuer Anwendungen und Anwendungsfälle, die MCUs in Kombination mit einer Form der KI-Beschleunigung nutzen können, um eine intelligente Steuerung in Edge-Geräten und Endpunkten zu ermöglichen. Diese KI-fähigen MCUs bieten eine einzigartige Kombination aus DSP-Funktionen für die Datenverarbeitung und maschinellem Lernen (ML) für Inferenzen und werden in so unterschiedlichen Anwendungen wie Schlüsselworterkennung, Sensorfusion und Vibrationsanalyse eingesetzt. Leistungsstärkere MCUs ermöglichen komplexere Anwendungen in der Bildverarbeitung und Bildgebung, etwa Gesichtserkennung, Fingerabdruckanalyse und Objekterkennung.
Neuronale Netze werden in KI/ML-Anwendungen wie Bildklassifizierung, Personenerkennung und Spracherkennung verwendet. Hierbei handelt es sich um Bausteine, die bei der Implementierung von Algorithmen für maschinelles Lernen verwendet werden und in großem Umfang lineare Algebraoperationen wie Skalarprodukte und Matrixmultiplikationen für die Inferenzverarbeitung, das Netzwerktraining und Gewichtsaktualisierungen nutzen. Wie Sie sich vorstellen können, erfordert die Integration von KI in hochmoderne Produkte eine erhebliche Rechenleistung der Prozessoren. Entwickler dieser neu aufkommenden KI-Anwendungen müssen den Anforderungen nach höherer Leistung, mehr Speicher und geringerem Stromverbrauch gerecht werden und dabei gleichzeitig die Kosten niedrig halten.
In der Vergangenheit war dies die Domäne von GPUs und MPUs mit leistungsstarken CPU-Kernen, großen Speicherressourcen und Cloud-Konnektivität für Analysen. In jüngerer Zeit sind KI-Beschleuniger verfügbar, die diese Aufgabe von der Haupt-CPU entlasten können. Andere Edge-Computing-Anwendungen wie Audio- oder Bildverarbeitung erfordern die Unterstützung schneller Mehrfachakkumulationsvorgänge. Entwickler entschieden sich oft dafür, dem System einen DSP hinzuzufügen, um Signalverarbeitungs- und Rechenaufgaben zu übernehmen. Alle diese Optionen bieten die erforderliche hohe Leistung, verursachen jedoch erhebliche Kosten für das System und verbrauchen tendenziell mehr Strom und sind daher nicht für kostengünstige Endgeräte mit geringem Stromverbrauch geeignet.
Wie können MCUs diese Lücke schließen?
Die Verfügbarkeit leistungsstärkerer MCUs ermöglicht die Verwirklichung von kostengünstigem, stromsparendem und hochmodernem AIoT. AIoT wird durch die erhöhte Verarbeitungskapazität neuerer MCUs sowie durch leichte neuronale Netzwerkmodelle ermöglicht, die besser für die ressourcenbeschränkten MCUs geeignet sind, die in diesen Endverbrauchsgeräten verwendet werden. KI in MCU-basierten IoT-Geräten ermöglicht eine Entscheidungsfindung in Echtzeit und eine schnellere Reaktion auf Ereignisse und bietet außerdem die Vorteile eines geringeren Bandbreitenbedarfs, eines geringeren Stromverbrauchs, einer geringeren Latenz, geringerer Kosten und einer höheren Sicherheit als MPU oder DSP. MCUs bieten außerdem schnellere Aufwachzeiten, was eine schnellere Inferenz und einen geringeren Stromverbrauch ermöglicht, sowie eine bessere Integration mit Speicher und Peripheriegeräten, um die Gesamtsystemkosten für kostensensible Anwendungen zu senken.
Cortex-M4/M33-basierte MCUs können die einfachsten KI-Aufgaben und Anwendungsfälle ausführen, wie z. B. Schlüsselworterkennung und vorausschauende Wartungsaufgaben mit geringeren Leistungsanforderungen. Wenn es jedoch um komplexere Anwendungsfälle geht, wie etwa KI-Vision-Aufgaben (Objekterkennung, Posenschätzung, Bildklassifizierung) oder Sprach-KI (Spracherkennung, NLP), ist ein Prozessor erforderlich. Leistungsstärker. Der ältere Cortex-M7-Kern kann einige dieser Aufgaben ausführen, die Inferenzleistung ist jedoch schlecht und liegt typischerweise nur im Bereich von 2 bis 4 fps.
Benötigt wird ein leistungsstärkerer Mikrocontroller mit KI-Beschleunigung.
Wir stellen die leistungsstarken KI-MCUs der RA8-Serie vor
Die neuen MCUs der RA8-Serie verfügen über einen Arm Cortex-M85-Kern, der auf der Arm v8.1M-Architektur und einer 7-stufigen superskalaren Pipeline basiert und die zusätzliche Beschleunigung bietet, die für intensive Signalverarbeitung oder neuronale Netzwerkverarbeitungsaufgaben erforderlich ist.
Der Cortex-M85 ist der leistungsstärkste Cortex-M-Kern und ist mit Helium™ ausgestattet, der M-Profile Vector Extension (MVE) von Arm, die mit der Arm v8.1M-Architektur eingeführt wurde. Helium ist eine Erweiterung des SIMD-Vektorverarbeitungsbefehlssatzes (Single Instruction Multiple Data), der die Leistung verbessern kann, indem mehrere Datenelemente mit einem einzigen Befehl verarbeitet werden, z. B. wiederholte multiplikative Akkumulationen über mehrere Daten. Helium beschleunigt die Signalverarbeitung und maschinelle Lernfunktionen auf ressourcenbeschränkten MCU-Geräten erheblich und ermöglicht eine beispiellose 4-fache Beschleunigung bei ML-Aufgaben und eine 3-fache Beschleunigung bei DSP-Aufgaben im Vergleich zum vorherigen Cortex-M7-Kern. In Kombination mit großem Speicher, erweiterter Sicherheit und einem umfangreichen Satz an Peripheriegeräten und externen Schnittstellen eignen sich RA8-MCUs ideal für Sprach- und Bildanwendungen mit künstlicher Intelligenz sowie für intensive Computeranwendungen, die Signalverarbeitungsunterstützung erfordern, wie z. B. Signalverarbeitung, Audio, JPEG Dekodierung und Motorsteuerung.
Was ermöglichen RA8-MCUs mit Helium?
Die Leistungssteigerung von Helium wird durch die Verarbeitung großer 128-Bit-Vektorregister erreicht, die mehrere Datenelemente (SIMD) mit einem einzigen Befehl speichern können. In der Ausführungsphase der Pipeline können sich mehrere Anweisungen überschneiden. Der Cortex-M85 ist ein Dual-Puls-CPU-Kern und kann zwei 32-Bit-Datenwörter in einem Taktzyklus verarbeiten, wie in Abbildung 1 dargestellt. Eine Multiplikations- und Akkumulationsoperation erfordert eine Speicherlast in einem Vektorregister, gefolgt von einer Multiplikationsakkumulation, die kann gleichzeitig mit dem Laden der nächsten Daten aus dem Speicher erfolgen. Durch die Überlagerung von Lasten und Multiplikationen erreicht die CPU die doppelte Leistung eines entsprechenden Skalarprozessors ohne Flächen- und Leistungseinbußen.
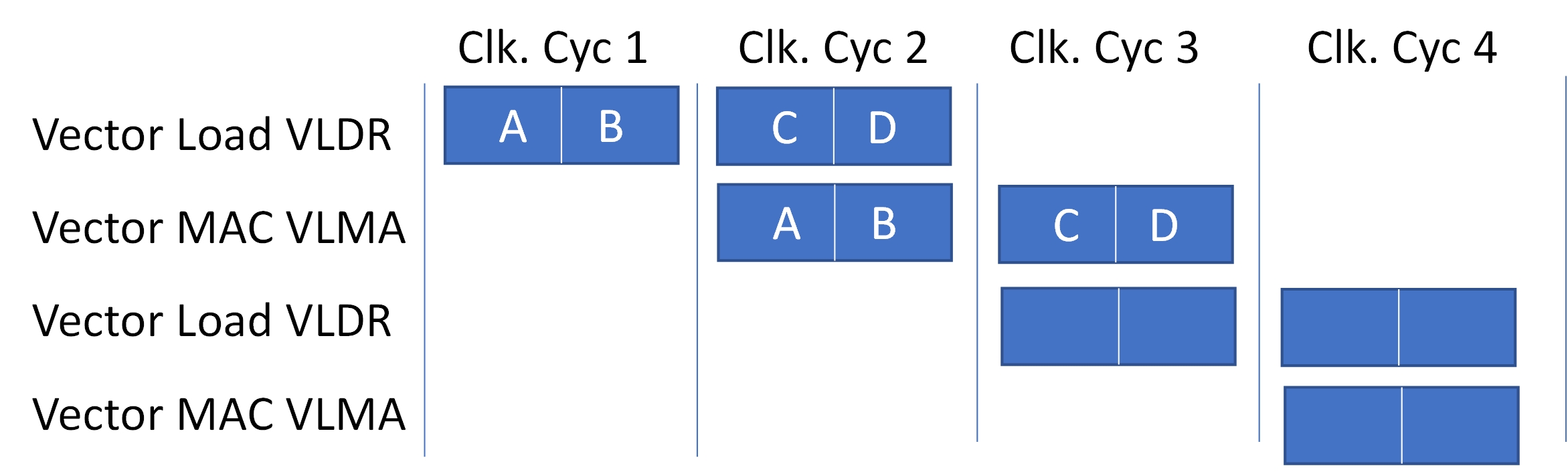
Abbildung 1: CM85 ist eine Dual-Pulse-CPU, das heißt, pro Taktzyklus können zwei 32-Bit-Wörter verarbeitet werden
Helium führt 150 neue Skalar- und Vektoranweisungen zur Signalverarbeitung und Beschleunigung des maschinellen Lernens ein, darunter:
- Low Cost Branch Extension (LOBE) für optimierte Branch- und Loop-Operationen und reduzierte Branch-Strafen
- Die Verzweigungsvorhersage ermöglicht die bedingte Ausführung jeder Verzweigung in einem Vektor und ermöglicht so eine effiziente Vektorisierung von komplexem bedingtem Code
- Vektor-Sammel-, Lade- und Streuspeicheranweisungen für Lese- und Schreibvorgänge an nicht zusammenhängenden Speicherorten, nützlich bei der Implementierung von Ringpuffern, die häufig bei der Implementierung von FIR-Filtern in DSP-Anwendungen verwendet werden.
- Arithmetische Operationen mit komplexen Zahlen wie Addition, Multiplikation und Rotation, die in DSP-Algorithmen verwendet werden
- DSP-Funktionen wie Ringpuffer für die FIR-Filterimplementierung, bitinvertierte Adressierung für FFT-Implementierungen und Formatkonvertierung in der Bild- und Videoverarbeitung mit Interleaving- und Deinterleaving-Anweisungen.
- Polynomiale Mathematik zur Unterstützung der Finite-Feld-Arithmetik, die in kryptografischen Algorithmen und bei der Fehlerkorrektur verwendet wird
- Native Unterstützung für 8-, 16- und 32-Bit-Festkomma-Ganzzahldaten, die in der Audio-/Bildverarbeitung und beim maschinellen Lernen verwendet werden, sowie Gleitkommadaten mit halber, einfacher und doppelter Genauigkeit, die in der Signalverarbeitung verwendet werden.
- Verbesserte Multiplikations-Akkumulations-Leistung (MAC) unterstützt zwei 32-Bit*32-Bit-MAC/Zyklus, vier 16-Bit*16-Bit-MAC/Zyklus und acht 8-Bit*8-Bit-MAC/Zyklus pro Taktzyklus
Diese Funktionen machen eine Helium-fähige MCU besonders geeignet für KI/ML- und DSP-artige Aufgaben ohne einen zusätzlichen DSP oder Hardware-KI-Beschleuniger im System und reduzieren außerdem Kosten und Stromverbrauch.
Vision AI und Grafikanwendung mit RA8D1 MCU
Renesas hat diese Leistungsverbesserung mit Helium in einigen KI/ML-Anwendungsfällen erfolgreich demonstriert und dabei eine deutliche Verbesserung gegenüber einer Cortex-M7-MCU gezeigt: in einigen Fällen mehr als das 3,6-fache.
Eine dieser Anwendungen ist eine KI-Anwendung zur Personenerkennung, die in Zusammenarbeit mit Plumerai, einem führenden Anbieter von KI-Lösungen im Bereich Sehvermögen, entwickelt wurde. Basierend auf der RA8D1-MCU wurde die kamerabasierte Personenerkennungs-KI-Lösung für den Helium-fähigen Arm Cortex-M85-Kern angepasst und optimiert und demonstrierte erfolgreich sowohl die Leistung des CM85- und Helium-Kerns als auch die Grafikfähigkeiten des RA8D1. Geräte.
Die mit Helium beschleunigte Anwendung erreicht eine 3,6-fache Leistungssteigerung gegenüber dem Cortex-M7-Kern und eine Bildrate von 13,6 fps, was für eine MCU ohne Hardwarebeschleunigung eine solide Leistung ist. Die Demonstrationsplattform erfasst Livebilder von einer OV7740-Bildsensor-Kamera mit einer Auflösung von 640 x 480 und präsentiert die Erkennungsergebnisse auf einem angeschlossenen 800 x 480 LCD-Display. Die Personenerkennungssoftware erkennt und verfolgt jede Person innerhalb des Kamerarahmens, auch wenn diese teilweise verdeckt ist, und zeigt auf dem Live-Kamerabildschirm überlagerte Begrenzungsrahmen um jede erkannte Person an.

Abbildung 2: Renesas People Detection AI Demo-Plattform, vorgestellt auf der Embedded World 2023
Die Plumerai People Detection-Software verwendet ein mehrschichtiges Faltungs-Neuronales Netzwerk, das mit über 32 Millionen beschrifteten Bildern trainiert wird. Die Schichten, die den Großteil der Gesamtlatenz ausmachen, sind diejenigen, die durch Helium beschleunigt werden, wie z. B. Conv2D und vollständig verbundene Schichten sowie Schichten mit tiefer Faltung und transponierter Faltung.
Das Kameramodul stellt Bilder im YUV422-Format bereit, die zur Anzeige auf dem LCD-Bildschirm in das RGB565-Format konvertiert werden. Die im RA2D8 integrierte 1D-Grafik-Engine passt dann die Größe an und konvertiert RGB565 in ABGR8888 mit einer Auflösung von 256 x 192 zur Eingabe in das neuronale Netzwerk. Die Personenerkennungssoftware läuft auf dem Cortex-M85-Kern, konvertiert dann das ARBG8888-Format in das Eingabeformat des neuronalen Netzwerkmodells und führt die Inferenzfunktion zur Personenerkennung aus. Zeichenfunktionen mit der 2D-Zeichen-Engine des RA8D1 werden verwendet, um die Kameraeingabe auf dem LCD-Bildschirm darzustellen und auch um Begrenzungsrahmen um erkannte Personen zu zeichnen und die Bildrate darzustellen. Die Personenerkennungssoftware verwendet etwa 1,2 MB Flash-Speicher und 320 KB SRAM, einschließlich Speicher für das 8888 x 256 ABGR192-Eingabebild.
Es wurde ein Benchmark durchgeführt, um die Latenz der Personenerkennungslösung von Plumerai sowie desselben neuronalen Netzwerks, das mit TFMicro läuft, mit den CMSIS-NN-Kernen von Arm zu vergleichen. Darüber hinaus wurde für Cortex-M85 die Leistung beider Lösungen auch mit deaktiviertem Helium (MVE) verglichen. Diese Benchmark-Daten zeigen die reine Inferenzleistung und berücksichtigen keine Latenz für Grafikfunktionen wie Bildformatkonvertierungen.
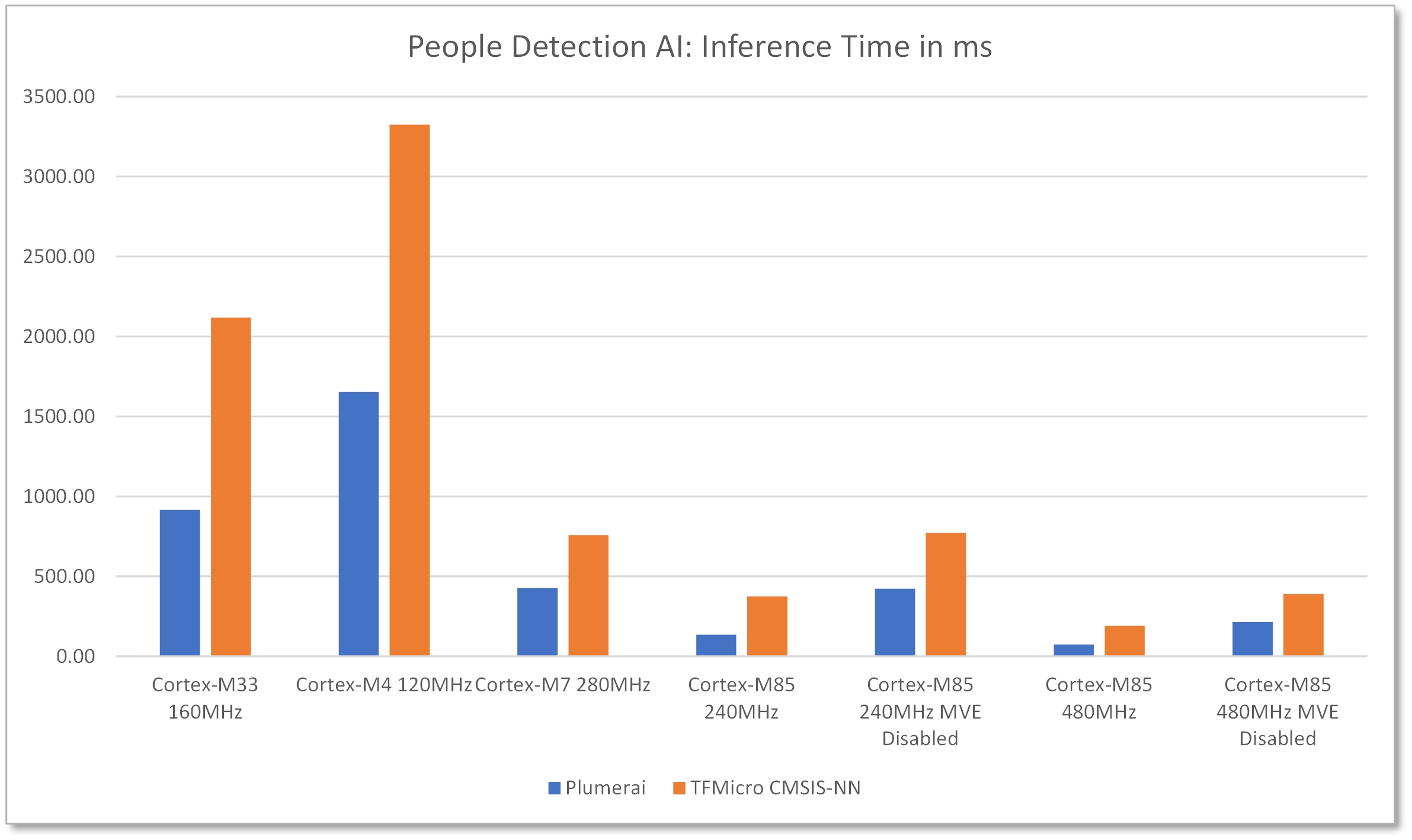
Abbildung 3: Die Personenerkennungsdemo von Renesas zeigte eine 3,6-fache Leistungsverbesserung gegenüber dem Cortex-M7-Kern
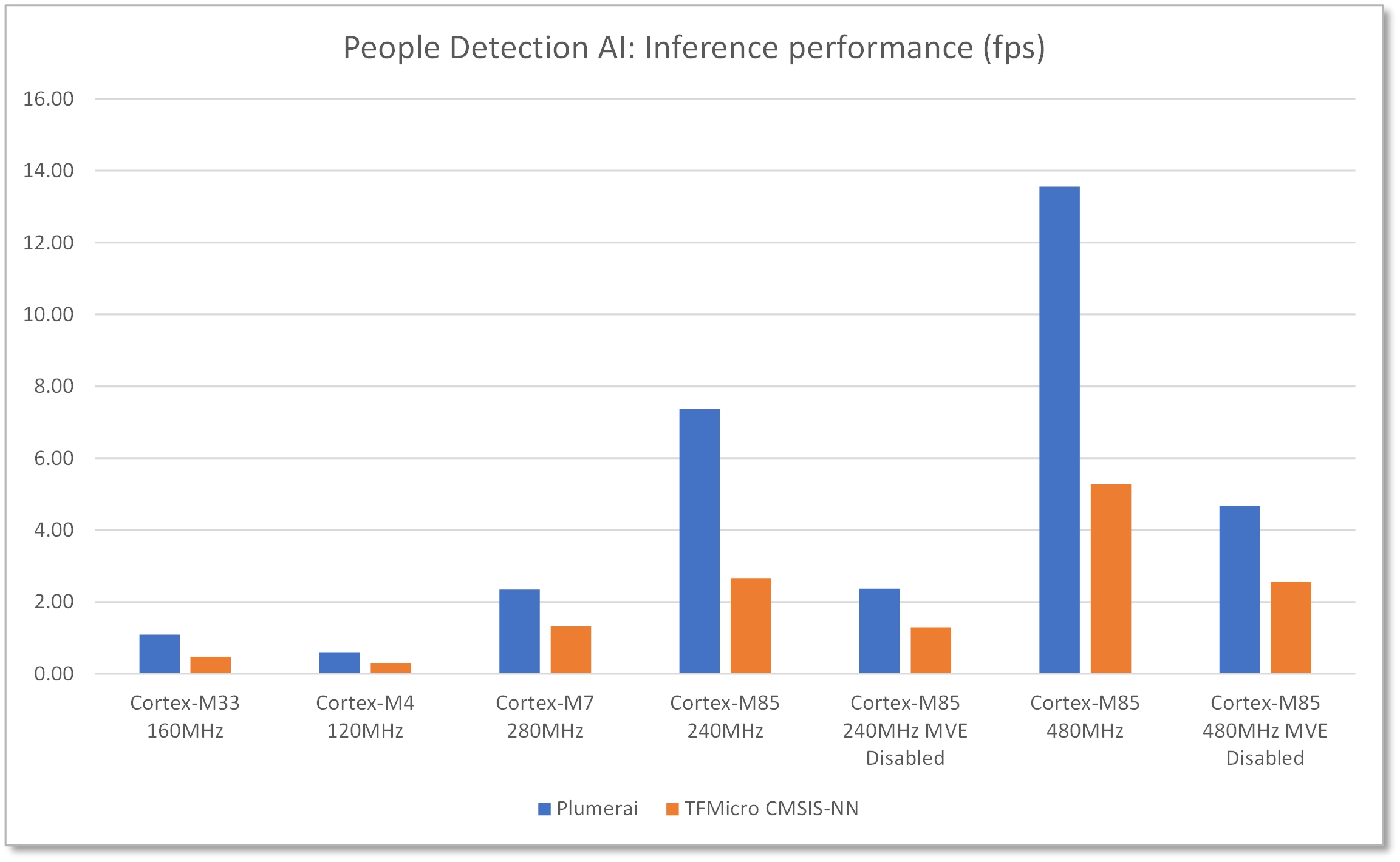
Abbildung 4: Inferenzleistung von 13,6 fps bei 480 MHz mit RA8D1 und aktiviertem Helium
Diese Anwendung nutzt alle im RA8D1 verfügbaren Ressourcen optimal aus: die hohe Leistung von 480 MHz, Helium für die Beschleunigung des neuronalen Netzwerks, ein großes FLASH und SRAM zum Speichern von Modelldaten und Eingabeaktivierungen sowie die Kamera zum Erfassen und Eingeben von Bildern/ Video und den Bildschirm, um die Erkennungsergebnisse anzuzeigen.
KI-Sprachanwendung mit RA8M1-MCU
Eine weitere solche Anwendung ist ein Anwendungsfall zur Erkennung von Sprachbefehlen, der auf dem RA8M1 läuft und ein tiefes neuronales Netzwerk (DNN) implementiert, das mit Tausenden verschiedener Stimmen trainiert wird und mehr als 40 Sprachen unterstützt. Diese Sprachanwendung stellt eine Verbesserung gegenüber der einfachen Schlüsselworterkennung dar und unterstützt eine modifizierte Form des natürlichen Sprachverständnisses (NLU), das sich nicht nur auf das Befehlswort oder die Befehlsphrase verlässt, sondern stattdessen nach der Absicht sucht. Dies ermöglicht die Verwendung einer natürlicheren Sprache, ohne dass man sich genaue Schlüsselwörter oder Phrasen merken muss.
Die Sprachimplementierung nutzt die SIMD-Anweisungen, die im heliumbetriebenen Cortex-M85-Kern verfügbar sind. RA8M1 ist mit seinem großen Speicher, der Unterstützung für die Audioerfassung und vor allem der hohen Leistung und ML-Beschleunigung, die durch den Cortex-M85- und Helium-Kern ermöglicht wird, eine natürliche Wahl für diese Art von Sprach-KI-Lösungen. Selbst die vorläufige Implementierung dieser Lösung mit und ohne Helium zeigt eine mehr als zweifache Verbesserung der Inferenzleistung gegenüber der Cortex-M7-basierten MCU, wie in Abbildung 5 dargestellt.
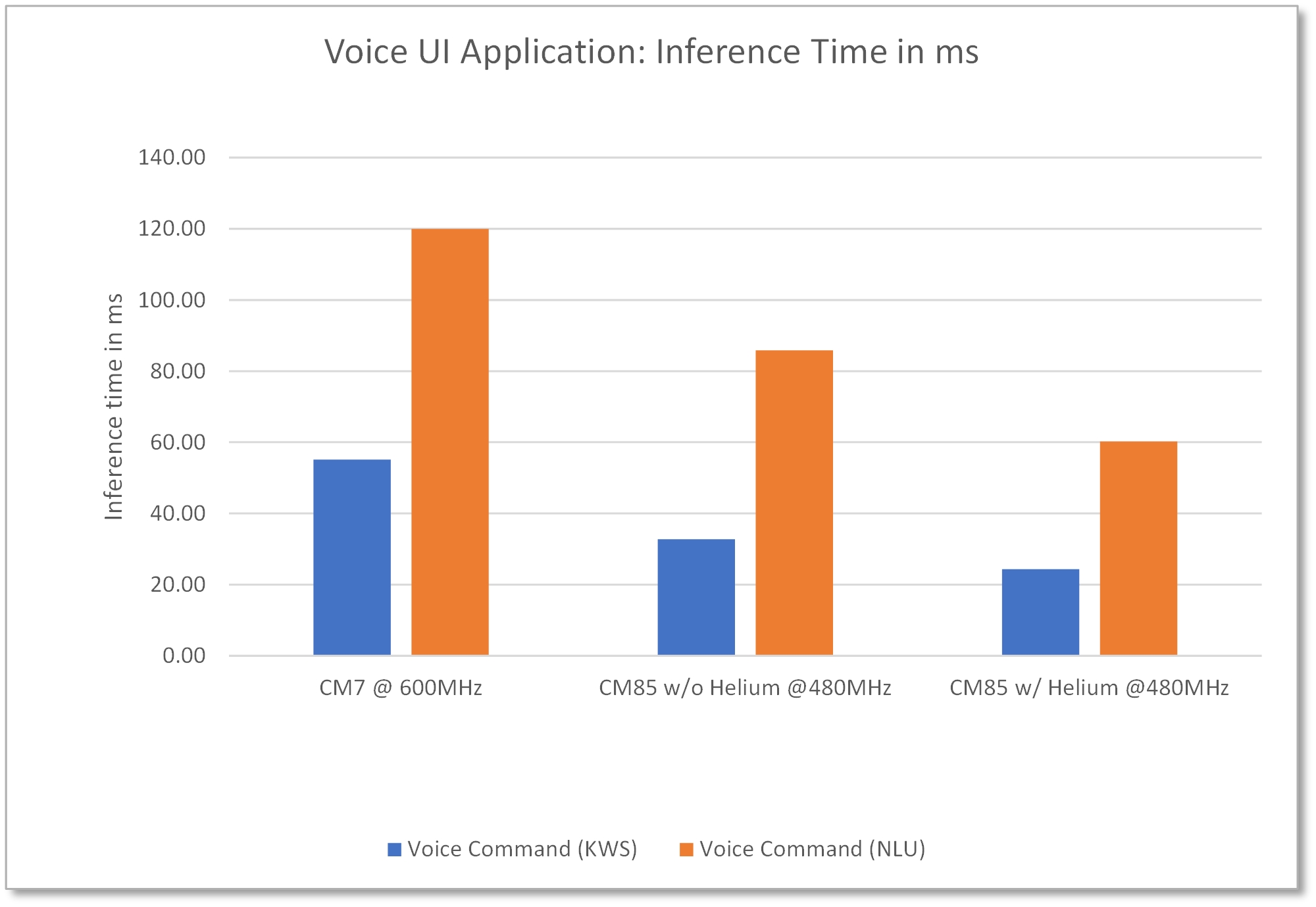
Abbildung 5: Die KI-Sprachanwendung auf der RA8M1-MCU zeigt CM85-Leistungsverbesserungen gegenüber CM7, ohne und mit Helium
Es ist offensichtlich, dass RA8-MCUs mit Helium die Leistung neuronaler Netzwerke erheblich verbessern können, ohne dass eine zusätzliche Hardwarebeschleunigung erforderlich ist, und bieten somit eine kostengünstige Option mit geringem Stromverbrauch für die Implementierung einfacherer KI-Anwendungsfälle und maschinelles Lernen.
Referenzen
Dieser Artikel bezieht sich auf die folgenden Ressourcen:
- „Arm® Helium™-Technologie, M-Profile Vector Extension (MVE) für Arm® Cortex®-M-Prozessoren“, von Jon Marsh, Arm
- „Einführung in die Armv8.1-M-Architektur“ von Joseph Yiu, Arm, Februar 2019
- Plumerai People Detection Demo auf MCU Renesas RA8D1




