
Dimensionamiento adecuado del hardware para un ML/AI óptimo en el Edge
Autor: Yann LeFaou, Associate Director de la unidad de negocio Touch and Gesture (TXFG) de Microchip.
El aprendizaje automático (ML) y la inteligencia artificial (IA, de la que el ML puede considerarse un subconjunto) se han implementado históricamente en plataformas informáticas de alto rendimiento y, más recientemente, en la nube. Sin embargo, en la actualidad ambos se están utilizando cada vez más en aplicaciones en las que el procesamiento se realiza cerca de la fuente de datos. Este procesamiento en el edge, ideal para los dispositivos IoT, significa que se necesitan enviar menos datos a la nube para su análisis. Entre las ventajas se incluyen un mejor rendimiento gracias a la reducción de la latencia y una mayor seguridad.
El ML/IA lleva el procesamiento edge al siguiente nivel al hacer posible la inferencia en el origen. Permite que un dispositivo IoT, por seguir con el ejemplo, aprenda y mejore a partir de la experiencia. Los algoritmos analizan los datos para buscar patrones y tomar decisiones informadas con tres formas en las que la máquina (o la IA) aprenderá: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje reforzado.
En el aprendizaje supervisado, la máquina utiliza datos etiquetados para el entrenamiento. Por ejemplo, una cámara de seguridad inteligente podría entrenarse utilizando fotos y videoclips de personas de pie, caminando, corriendo o llevando cajas. Los algoritmos de ML supervisado incluyen la regresión logística y el algoritmo Naive Bayes, que requieren retroalimentación para seguir perfeccionando los modelos sobre los que se realizarán las predicciones.
El aprendizaje no supervisado utiliza datos sin etiquetar y algoritmos como el agrupamiento K-Means y el análisis de componentes principales para identificar patrones. Es ideal para la detección de anomalías. Por ejemplo, en un escenario de mantenimiento predictivo o en una aplicación de imágenes médicas, la máquina señalaría situaciones o aspectos de la imagen que son inusuales basándose en el modelo de «normalidad» que ha construido y mantiene.
El aprendizaje reforzado es un proceso de «prueba y error». Al igual que en el aprendizaje supervisado, se requiere retroalimentación, pero en lugar de simplemente corregir la máquina, la retroalimentación se trata como una recompensa o una penalización. Entre los algoritmos se incluyen Monte Carlo y Q-learning.
En los ejemplos anteriores, un elemento común es la visión embebida, que se hace «inteligente» mediante la incorporación de ML/IA, y cualquier otra aplicación puede beneficiarse de la inferencia basada en la visión en el origen. Además, la visión embebida inteligente puede utilizar partes del espectro que no son visibles para el ojo humano, como el infrarrojo (utilizado para la imagen térmica) y el ultravioleta.
Si se proporciona a un sistema ML/AI edge otros datos, como lecturas de temperatura y niveles de vibración de transductores, los dispositivos industriales IoT no solo pueden desempeñar un papel importante en la estrategia de mantenimiento predictivo de una organización, sino que también pueden proporcionar alertas tempranas de fallos inesperados y, por lo tanto, ayudar a proteger la maquinaria, los productos y el personal.
Sistemas Embebidos
Como mencionamos al principio, el ML/IA requería inicialmente considerables recursos informáticos. Hoy en día, dependiendo de la complejidad de la máquina, se pueden utilizar componentes más asociados a los sistemas embebidos (como los dispositivos IoT) para implementar el ML y la IA.
Por ejemplo, la detección y clasificación de imágenes se puede implementar en matrices de puertas programables en campo (FPGA) y en unidades de microprocesador (MPU). Además, aplicaciones relativamente sencillas, como la monitorización y el análisis de vibraciones (para el mantenimiento predictivo, por ejemplo), se pueden implementar en una unidad de microcontrolador (MCU) de 8 bits.
Asimismo, mientras que el ML/IA requería inicialmente personal científico de datos altamente cualificado para desarrollar algoritmos de reconocimiento de patrones y modelos que pudieran actualizarse automáticamente para poder realizar predicciones, esto ya no es así. Los ingenieros de sistemas embebidos, ya familiarizados con el procesamiento edge, disponen ahora del hardware, el software, las herramientas y las metodologías necesarios para diseñar productos habilitados para ML/IA. Además, muchos modelos y datos para el entrenamiento de máquinas están disponibles gratuitamente y muchos proveedores de circuitos integrados ofrecen entornos de desarrollo integrado (IDE) y suites de desarrollo para acelerar la creación de aplicaciones de ML/IA.
Tomemos, por ejemplo, el MPLAB X IDE de Microchip. Este programa de software incorpora herramientas que ayudan a los ingenieros a descubrir, configurar, desarrollar, depurar y cualificar diseños embebidos para muchos de los dispositivos de la empresa. Un complemento del paquete de desarrollo de aprendizaje automático permite transferir los modelos de ML directamente al hardware de destino. Este paquete utiliza el denominado aprendizaje automático (AutoML), que es el proceso de automatización de muchas tareas iterativas y que requieren mucho tiempo, como el desarrollo y el entrenamiento de modelos (véase la figura 1).
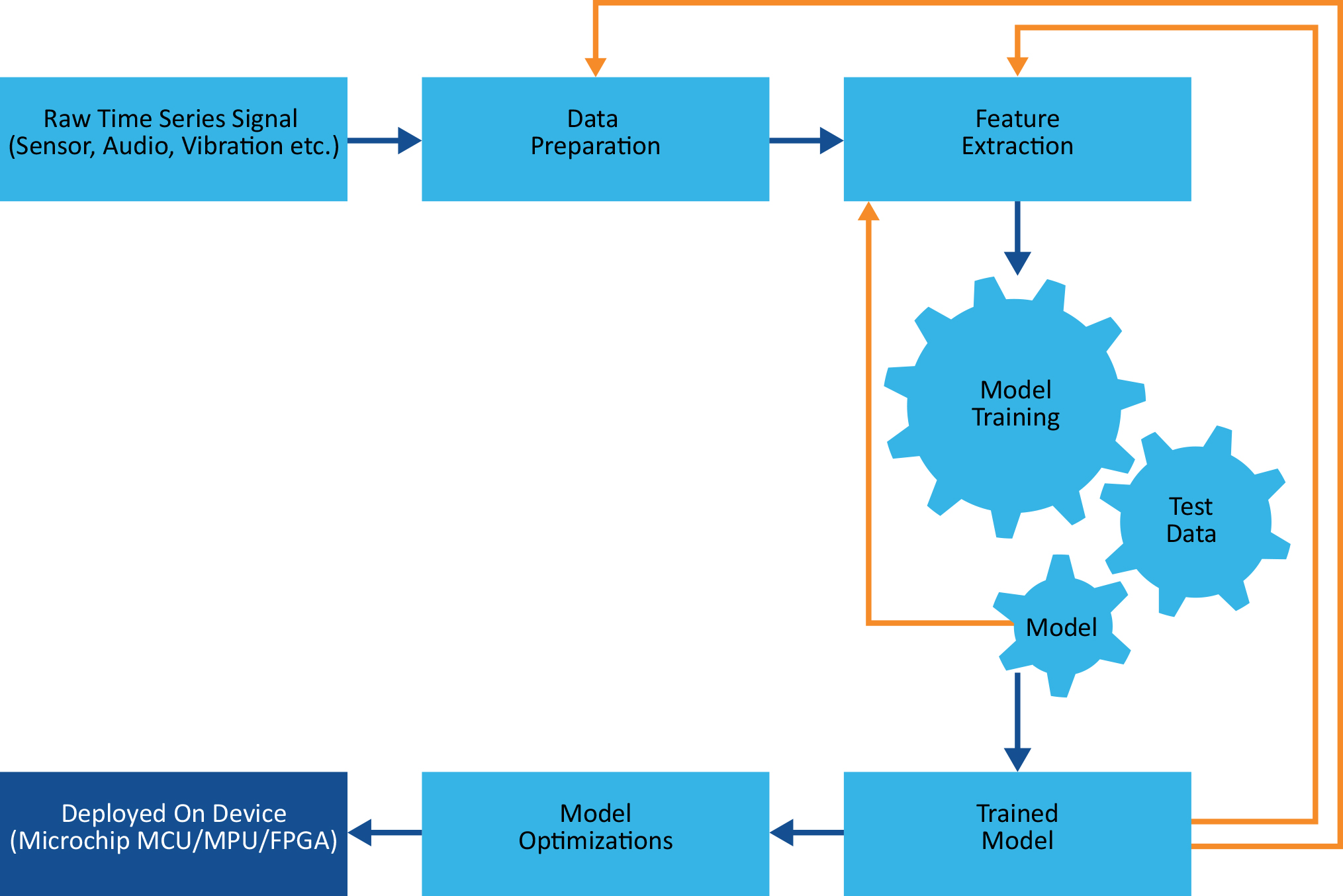
Figura 1: El desarrollo de modelos de ML/IA es un proceso iterativo
Aunque estos pasos iterativos pueden automatizarse, la optimización del diseño es otra cuestión. Incluso los ingenieros con experiencia en el diseño de aplicaciones de procesamiento edge pueden tener dificultades con algunos aspectos del ML/AI. Será necesario hacer muchas concesiones entre el rendimiento del sistema (determinado en gran medida por el tamaño/complejidad del modelo y el volumen de datos), el consumo de energía y el coste. En cuanto a los dos últimos, la figura 2 ilustra la relación inversa entre el rendimiento (requerido) y el coste, e indica el consumo de energía de los tipos de dispositivos de Microchip utilizados en aplicaciones típicas de inferencia de ML.

Figura 2: Arriba, ejemplos de tipos de dispositivos y aplicaciones de inferencia de ML en las que se utilizan habitualmente.
Diseño para factores de forma pequeños
Como se ha mencionado, incluso los MCU de 8 bits pueden utilizarse para algunas aplicaciones de ML. Una de las cosas que lo hace posible y que contribuye en gran medida a introducir el ML/AI en la comunidad de ingenieros es la popularidad del tinyML, que permite ejecutar modelos en microprocesadores con recursos limitados.
Podemos ver las ventajas de esto si tenemos en cuenta que un MCU o MPU de gama alta para aplicaciones de ML/IA suele funcionar a una velocidad de entre 1 y 4 GHz, necesita entre 512 MB y 64 GB de RAM y utiliza entre 64 GB y 4 TB de NVM para el almacenamiento. Además, consumen entre 30 y 100 W de potencia. Por su parte, tinyML está destinado a MCUs que funcionan a entre 1 y 400 MHz, tienen entre 2 y 512 KB de RAM y utilizan entre 32 KB y 2 MB de memoria no volátil para el almacenamiento. El consumo de energía suele oscilar entre 150 µW y 23,5 mW, lo que resulta ideal para aplicaciones que funcionan con baterías, dependen en gran medida de la energía recolectada o se alimentan por inducción.
Las claves para implementar tinyML residen en la captura y preparación de datos y en la generación y mejora de modelos. De estos, la captura y preparación de datos son esenciales si se desea disponer de datos significativos (un conjunto de datos) a lo largo de todo el flujo del proceso de ML (véase la figura 3).

Figura 3: Flujo del proceso de aprendizaje automático.
Para fines de formación, se necesitan conjuntos de datos para máquinas supervisadas (y semisupervisadas). En este caso, un conjunto de datos es una recopilación de datos que ya están ordenados de alguna manera. Como se ha mencionado, en los sistemas supervisados los datos están etiquetados, por lo que, en nuestro ejemplo de la cámara de seguridad inteligente, la máquina se entrenaría utilizando fotos de personas de pie, caminando y corriendo (entre otras cosas). El conjunto de datos podría crearse manualmente, aunque hay muchos disponibles en el mercado, como MPII Human Pose, que incluye alrededor de 25.000 imágenes extraídas de vídeos en línea.
Sin embargo, el conjunto de datos debe optimizarse para su uso. Un exceso de datos llenará rápidamente la memoria. Si los datos son insuficientes, la máquina no podrá realizar predicciones o estas serán erróneas o engañosas.
Además, el modelo de ML/IA debe ser pequeño. En este sentido, un método de compresión muy popular es el «weight prunning», en la que se establece en cero el peso de las conexiones entre algunas neuronas del modelo, lo que significa que la máquina no necesita incluirlas al realizar inferencias a partir del modelo. Las neuronas también se pueden «podar» (prunning). Otra técnica de compresión es la cuantificación. Esta reduce la precisión de los parámetros, sesgos y activaciones de un modelo convirtiendo los datos de un formato de alta precisión, como el de punto flotante de 32 bits (FP32), a un formato de menor precisión, como el entero de 8 bits (INT8).
Con un conjunto de datos optimizado y un modelo compacto, se puede seleccionar un MCU adecuado. En este sentido, existen marcos que facilitan esta tarea. Por ejemplo, el marco/flujo TensorFlow permite seleccionar un nuevo modelo TensorFlow o volver a entrenar uno existente. A continuación, se puede comprimir en un búfer plano utilizando TensorFlow Lite Converter, cargarse en el destino y cuantificarse.
Resumen
El ML y la IA utilizan métodos algorítmicos para identificar patrones/tendencias en los datos y realizar predicciones. Al situar el ML/IA en la fuente de datos (edge), las aplicaciones pueden realizar inferencias y tomar medidas sobre el terreno y en tiempo real, lo que hace que el sistema global sea más eficiente (en términos de rendimiento y potencia) y más seguro.
Gracias a la disponibilidad de hardware, IDE, herramientas y kits de desarrollo, marcos, conjuntos de datos y modelos de código abierto adecuados, los ingenieros pueden desarrollar con relativa facilidad productos de procesamiento periférico habilitados para ML/IA.
Llegan tiempos emocionantes para los ingenieros de sistemas embebidos y para el sector en su conjunto. Sin embargo, es importante no excederse en la ingeniería. Se puede dedicar mucho tiempo y dinero al desarrollo de aplicaciones destinadas a chips con más recursos de los necesarios, que consumen más energía y son más caros.



: lo que significa para el Edge Computing")
