
Recientemente, la inteligencia artificial (IA) y el aprendizaje automático (ML) han experimentado avances significativos impulsados por algoritmos avanzados y el rápido aumento del rendimiento de las unidades de procesamiento gráfico (GPU). Este progreso, combinado con enormes conjuntos de datos de entrenamiento, ha cambiado las necesidades de almacenamiento de datos, lo que ha llevado a un aumento de la demanda de sistemas de almacenamiento especializados de alta capacidad y alto rendimiento. Si bien mantener una alta eficiencia en el entrenamiento y aprovechar al máximo la infraestructura de GPU es un reto clave, los requisitos para el almacenamiento de datos de IA son más amplios.
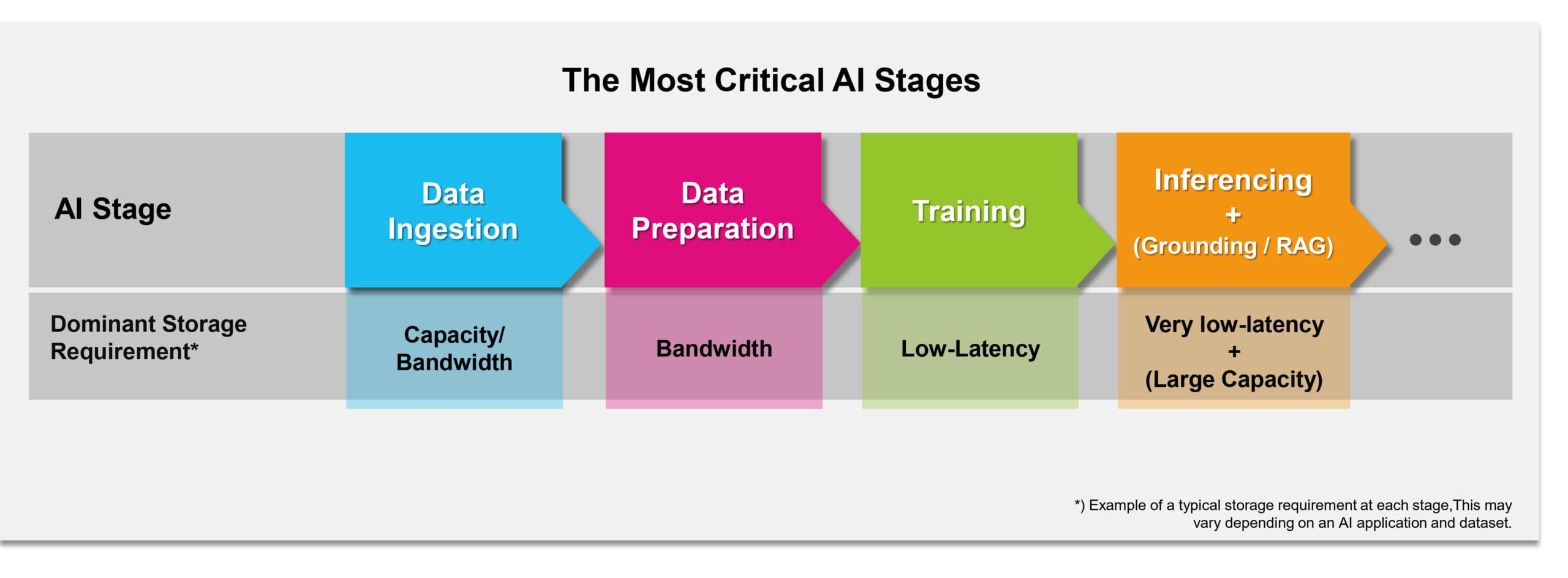 Figura 1. Las etapas más críticas en el procesamiento de datos de IA desde la perspectiva del almacenamiento
Figura 1. Las etapas más críticas en el procesamiento de datos de IA desde la perspectiva del almacenamiento
El ciclo de procesamiento de datos de IA en los servidores empresariales modernos implica varias etapas cruciales desde la perspectiva del almacenamiento: ingesta de datos, preparación de datos, entrenamiento de IA e inferencia de IA (Figura 1). Los modelos de lenguaje grandes (LLM) también pueden incorporar fundamento a través de la generación aumentada por recuperación (RAG). Veamos los retos de almacenamiento en cada etapa.
Ingesta de datos
Esta es una de las primeras etapas, en la que se recopilan archivos de diversas fuentes en una única ubicación de almacenamiento. Puede implicar el traslado de datos desde fuentes como bases de datos, contenido de usuarios y sensores a un almacenamiento centralizado. La carga de trabajo requiere mucha capacidad, ya que las aplicaciones de IA/ML generan operaciones de alto rendimiento y abarcan una amplia variedad de cargas de trabajo de almacenamiento. Las cargas de trabajo varían; algunas requieren muchas escrituras secuenciales (lotes grandes), mientras que otras pueden dar lugar a un patrón de acceso aleatorio (streaming, tiempo real, pequeños bloques entrelazados). A menudo, los datos de entrada deben almacenarse rápidamente.
Preparación de datos
En esta etapa, los datos se limpian, se transforman y se diseñan para crear un conjunto de datos estructurado y potencialmente enriquecido para el entrenamiento y la evaluación de modelos. Esto implica la limpieza, el filtrado, la normalización, el aumento y el etiquetado. La carga de trabajo de E/S puede ser bastante intensa debido al frecuente acceso, modificación y reescritura de los datos. Un gran ancho de banda de escritura resulta muy beneficioso.
Entrenamiento del modelo
Esta fase pasa de requerir un uso intensivo de datos a ser más sensible a la latencia y es una de las más exigentes en cuanto a almacenamiento. La carga de trabajo de almacenamiento depende en gran medida del modelo, el conjunto de datos y el proceso de entrenamiento. El entrenamiento de IA suele requerir un alto rendimiento de datos para cargar grandes conjuntos de datos y realizar puntos de control frecuentes. Si bien el alto rendimiento es crucial, el almacenamiento de baja latencia ayuda a mejorar la eficiencia general. Reduce el tiempo de acceso y carga de los bloques de datos, lo cual es importante para el acceso frecuente durante el entrenamiento, y reduce el tiempo de comprobación, lo que se traduce en menos tiempo de inactividad de la GPU. El ancho de banda de lectura necesario varía mucho en función de la limitación de cálculo del modelo y el tamaño de la entrada, como se muestra al contrastar las demandas de diferentes modelos de imagen (p. ej., ResNet-50 frente a 3D U-Net). Una solución bien diseñada debe ofrecer un rendimiento de lectura fiable con la latencia necesaria para un uso óptimo de la GPU.
Inferencia
Esta etapa se produce después del entrenamiento, cuando se utiliza el modelo para realizar predicciones sobre nuevos datos. Se caracteriza por operaciones de lectura intensiva que requieren latencias estables y muy bajas. La inferencia en tiempo real exige un acceso a los datos a alta velocidad de forma constante. El almacenamiento para IA desempeña un papel importante en la gestión de las cargas de inferencia. A medida que cambian las cargas de inferencia, el sistema debe adaptarse rápidamente cargando los modelos de IA desde el almacenamiento a la memoria de la GPU, lo que requiere una latencia y un ancho de banda de almacenamiento suficientes para evitar cuellos de botella y la infrautilización de la GPU.
El fundamento de LLM (RAG) es un proceso que utiliza modelos de lenguaje grandes (LLM) con conocimiento externo. El fundamento eficiente mediante RAG requiere una respuesta de almacenamiento de baja latencia para la recuperación en tiempo real de documentos o información relevantes. A menudo, esto implica acceder a fragmentos de datos específicos, como incrustaciones, lo que hace que el rendimiento de lectura aleatoria sea importante. La vectorización de datos de propiedad para RAG crea incrustaciones que multiplican el tamaño de los datos. Debido a estos requisitos de acceso, el rendimiento de lectura aleatoria puede ser a menudo importante para cumplir con los tiempos de respuesta esperados al generar respuestas para los usuarios finales.
Qué tecnología de SSD utilizar
La celda de triple nivel (TLC) es la tecnología Flash dominante, complementada por la celda de nivel cuádruple (QLC). Las unidades BiCS FLASH™ de KIOXIA incluyen ambas tecnologías en su gama. Mientras que la QLC se utiliza cuando se requieren capacidades extremadamente grandes (>60 TB), la TLC sigue estando presente para aquellos casos que necesitan latencias cortas, alto rendimiento y una resistencia razonablemente alta.
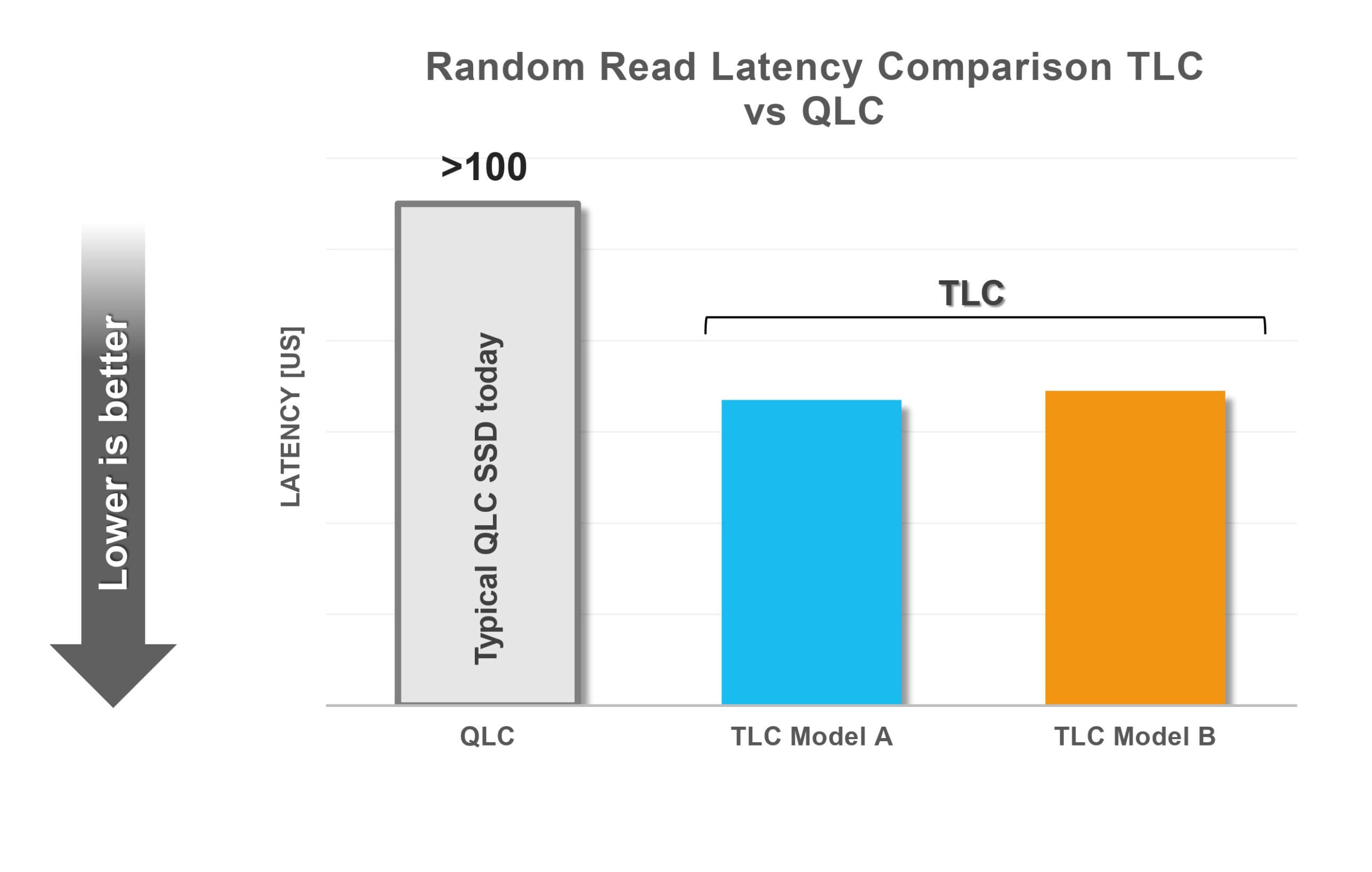
Figura 2. Mientras que las unidades QLC satisfacen las necesidades de capacidades extremadamente grandes, las unidades TLC desempeñan un papel importante en los casos que requieren una baja latencia.
Las unidades QLC actuales tienen latencias más altas que sus homólogas TLC; véase la Figura 2. Las soluciones QLC pueden requerir una costosa memoria de clase de almacenamiento (SCM) para el almacenamiento en caché con el fin de mejorar la resistencia y el rendimiento, lo que podría aumentar los costes generales de almacenamiento. A la hora de elegir la tecnología SSD, es necesario tener muy en cuenta estos factores.
Consideraciones sobre el almacenamiento de datos
Para las etapas de ingesta y preparación de datos, las SSD se consideran una opción óptima como medio de almacenamiento debido a su alto rendimiento y a su capacidad para gestionar de forma eficiente cargas de trabajo que requieren un gran ancho de banda.
Debido a sus rápidas velocidades de lectura y escritura, la DRAM se utiliza normalmente para datos a los que se debe acceder de forma rápida y frecuente, como los conjuntos de datos de trabajo durante el entrenamiento de modelos, en los que los parámetros se actualizan constantemente, o para mantener los pesos de una red neuronal durante la inferencia. Sin embargo, algunos modelos de IA pueden superar la capacidad de la DRAM de la GPU disponible de forma local, lo que crea la necesidad de almacenar los datos en el siguiente almacenamiento más rápido, como las unidades SSD NVM Express® (NVMe®).
La eficiencia energética de los sistemas de almacenamiento de datos de IA puede afectar a la capacidad de entrenamiento general. Las investigaciones demuestran que, en algunos casos, el almacenamiento y el preprocesamiento pueden consumir más energía que las GPU, lo que podría limitar la capacidad de entrenamiento debido a los límites de energía fijos de los centros de datos. Por lo tanto, al diseñar sistemas de IA se debe tener en cuenta la eficiencia del almacenamiento y de las unidades SSD. KIOXIA se centra en optimizar la eficiencia energética de sus unidades SSD, manteniendo un consumo moderado incluso con capacidades PCIe® 5.0 de alto rendimiento, lo que libera energía para las GPU.
En el caso de la inferencia de LLM, el planteamiento RAG requería tradicionalmente una cantidad significativa de DRAM (p. ej., para los algoritmos Hierarchical Navigable Small World, HNSW), lo que hacía que el escalado fuera caro y difícil. Las soluciones basadas en SSD, como las creadas con Microsoft DiskANN y KIOXIA AiSAQ™ (ANNS con cuantificación de productos y almacenamiento integral), ofrecen una alternativa rentable y escalable a las costosas soluciones basadas en DRAM, al trasladar parcial o totalmente las bases de datos vectoriales a las SSD. KIOXIA AiSAQ™ tiene como objetivo reducir al mínimo el espacio ocupado por la DRAM sin degradar significativamente el rendimiento.
Puntos de control en IA
Los puntos de control en IA son cruciales debido a la naturaleza intensiva en recursos y la larga duración del entrenamiento de los modelos de IA modernos, que puede llevar meses. Los fallos son comunes en infraestructuras complejas con ciclos de entrenamiento largos. Los estudios muestran tasas de fallo significativas (p. ej., hasta un 43,4 % para las tareas que más recursos consumen, hasta siete por semana con 128 GPU); véase la Figura 3.
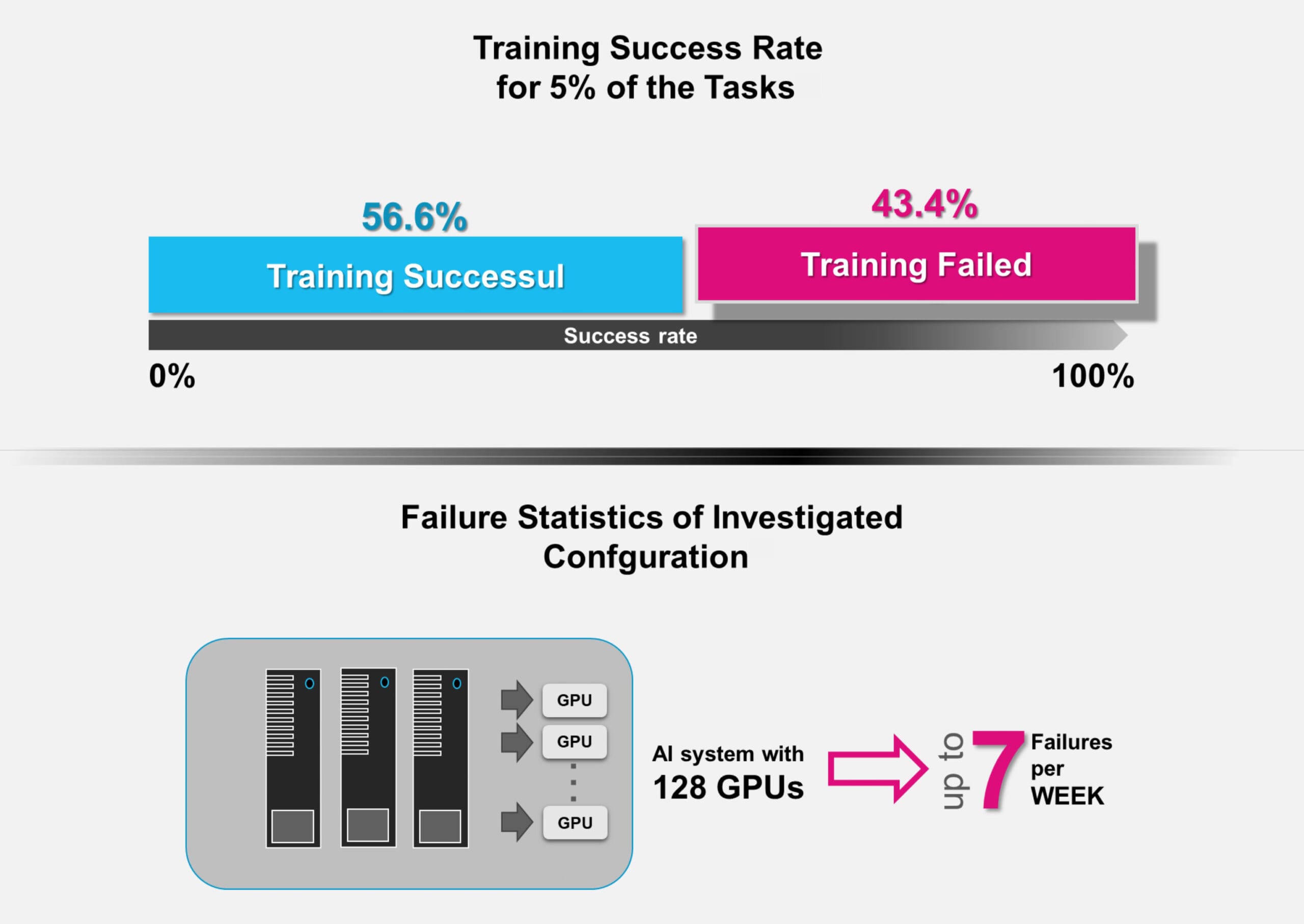
Figura 3. Tasas de fallo para el 5 % de las tareas que más recursos consumen: los sistemas de IA con 128 GPU pueden sufrir hasta siete fallos por semana
Los puntos de control son instantáneas periódicas del estado del modelo (parámetros, pesos, estados del optimizador) que permiten recuperar una configuración estable reciente. Los puntos de control añaden una sobrecarga al tiempo de entrenamiento (una media del 12 %, hasta un 43 % en los peores casos).
El ancho de banda de escritura necesario para los puntos de control depende del tamaño del modelo y del límite de tiempo permitido. Por ejemplo, para almacenar un modelo de 530 000 millones de parámetros (7420 GB) en 72 segundos se requiere un ancho de banda de escritura de 103,1 GB/s para mantener la sobrecarga en el 1 %. Si el ancho de banda de escritura es menor (p. ej., 10,3 GB/s), la parte de los puntos de control aumenta significativamente (p. ej., un 10 %), lo que reduce directamente el tiempo disponible para el entrenamiento.
Es esencial un alto ancho de banda de escritura desde el almacenamiento para llevar a cabo puntos de control eficientes y maximizar el tiempo de entrenamiento. La protección de los datos de entrenamiento es vital, ya que estos son muy valiosos. El cifrado por hardware es más eficiente que el cifrado por software. Las unidades de autocifrado (SED) protegen los datos en reposo cifrándolos dentro de la SSD, lo que impide el acceso a otros sistemas sin la contraseña. Las SSD SED de KIOXIA cumplen con el estándar del Trusted Computing Group (TCG) y realizan un cifrado sobre la marcha con aceleración por hardware, sin introducir latencia visible ni reducción del rendimiento.
Otros aspectos relacionados con las unidades SSD en los sistemas de IA
Las unidades SSD de alta capacidad actuales ofrecen ventajas significativas con respecto a las unidades de la generación anterior en cuanto al coste total de propiedad (TCO), debido a la consolidación de la energía, la refrigeración y otros ahorros operativos, lo que las hace especialmente adecuadas para soluciones de almacenamiento centradas en la IA. Sin embargo, es importante reconocer que el almacenamiento solo representa una pequeña parte de los costes totales de un sistema de IA, pero puede influir significativamente en la eficiencia general. Por lo tanto, a diferencia de los sistemas de almacenamiento convencionales, las decisiones relativas a la selección de unidades SSD deben basarse principalmente en requisitos técnicos y no únicamente en el coste.
Los sistemas de almacenamiento de IA deben proporcionar un rendimiento alto y constante con latencias bajas y predecibles bajo cargas de trabajo variables para evitar la infrautilización de la GPU mientras se esperan los datos. Las unidades SSD deben poseer estas capacidades, proporcionando latencias bajas constantes y operaciones de E/S por segundo (IOPS) estables, adaptándose de manera eficiente a las cargas de trabajo cambiantes.
Para el almacenamiento NVMe™ local cerca de las GPU, el formato estándar para empresas y centros de datos (EDSFF) ofrece una mejor refrigeración gracias a su menor altura y grosor, lo que permite un mejor flujo de aire hacia las GPU. El formato EDSFF también proporciona una mayor calidad de señal para PCIe® 5.0 y futuras interfaces como PCIe® 6.0 en comparación con el formato heredado de 2,5 pulgadas. El EDSFF también permite envolventes de potencia más altas (hasta 40 W o 70 W) en comparación con las de 2,5 pulgadas (hasta 25 W).
Los sistemas GPU modernos integran unidades NVMe™ conectadas localmente con DRAM como capa de alta velocidad para almacenar en caché o preparar grandes conjuntos de datos que superan la capacidad de la DRAM. Esto reduce la necesidad de atravesar la estructura de la red, lo que ofrece ventajas de baja latencia y rendimiento. NVIDIA GPUDirect Storage (GDS) permite realizar transferencias directas de datos desde el almacenamiento NVMe™ local o remoto a la memoria de la GPU, lo que mejora el rendimiento de E/S y reduce la latencia al eliminar el «búfer de rebote» de la ruta de datos.
Conclusión
Las unidades SSD avanzadas son fundamentales en los centros de datos de IA modernos para mantener las GPU saturadas y lograr una alta eficiencia. Las unidades PCIe® 5.0 de KIOXIA, como la serie CM7 de doble puerto y alto rendimiento, y las series CD8P y XD8 de un solo puerto, proporcionan una base excelente para la infraestructura de almacenamiento de datos de IA. Están diseñadas para satisfacer las demandas de los sistemas de IA en las etapas de ingesta, preparación, entrenamiento e inferencia de datos, lo que permite a los centros de datos centrarse en las aplicaciones de IA con confianza en las unidades SSD como un componente central robusto y fiable.



 de KIOXIA obtienen la certificación Microsoft Windows Server 2022")

