
Autora: Kavita Char, Gerente Principal de Marketing de Producto, Renesas
Introducción: ¿Por qué IA Edge?
Se ha producido un cambio de paradigma en el mercado de la IA. Anteriormente, el procesamiento de IA se realizaba principalmente en la nube. Los dispositivos terminales recopilaban datos de los sensores y los enviaban a la nube para el procesamiento de inferencia y la toma de decisiones, y los resultados se enviaban de vuelta a los dispositivos terminales. Este enfoque presentaba mayor latencia, mayor consumo de energía, riesgos de seguridad y requería un gran ancho de banda para la transmisión de datos a la nube. IDC estima que 79,4 ZB de datos se enviarán desde dispositivos IoT a la nube en 2025.
Por estas razones, existe una tendencia creciente hacia la inferencia de IA en el Edge, que permite respuestas rápidas en tiempo real y una mayor privacidad y seguridad de los datos, a la vez que evita la latencia y los costos asociados con la conexión a la nube. Esto también reduce el consumo de energía, lo que la hace adecuada para aplicaciones de IoT y de consumo alimentadas por batería. Por lo tanto, la IA en el Edge ofrece ventajas como autonomía, menor latencia, menor consumo de energía, menores costos con menor ancho de banda a la nube y mayor seguridad, todo lo cual la hace atractiva para aplicaciones nuevas y emergentes.
Existen diversas soluciones que abordan el mercado de la IA de borde. La elección entre una MPU y una MCU para la implementación de IA depende de los requisitos específicos de la aplicación. Las MPU son adecuadas para aplicaciones complejas que requieren una alta potencia de procesamiento, mientras que las MCU son ideales para aplicaciones de bajo consumo y con costes ajustados, donde el procesamiento en tiempo real y la eficiencia energética son cruciales.
Necesidad de aceleradores de IA dedicados
El procesamiento de redes neuronales requiere diversas operaciones de álgebra lineal, productos escalares y una serie de multiplicaciones, convoluciones y transposiciones de matrices rápidas y paralelas. Esto exige una mayor potencia computacional en los procesadores. Los fabricantes de MCU están introduciendo dispositivos que incluyen núcleos de CPU avanzados con mejoras para soportar operaciones de DSP e IA/ML, como las extensiones vectoriales de helio en el núcleo Arm Cortex-M85. Los fabricantes de MCU también están integrando una Unidad de Procesamiento Neural (NPU) en la MCU, diseñada para acelerar las tareas de inferencia de IA.
Ventajas de las NPU:
- Mayor rendimiento de procesamiento de IA/ML: Una NPU cuenta con hardware dedicado para ejecutar las operaciones principales de los modelos de redes neuronales, como multiplicaciones de matrices y convoluciones, de forma más eficiente y con menor latencia que el núcleo de la CPU. Las NPU están optimizadas para la aritmética de menor precisión (entero de 8/4 bits) utilizada en los modelos de IA, lo que reduce la complejidad, el uso de memoria y el consumo de energía sin reducir la precisión de la inferencia.
- Particionado eficiente del sistema: Las NPU gestionan las tareas de IA y liberan la CPU principal para realizar el preprocesamiento y el posprocesamiento de los datos de IA, así como para ejecutar el código de la aplicación y otras tareas del sistema, como la seguridad, las interfaces de sensores y las comunicaciones, lo que se traduce en mejoras en el rendimiento del sistema.
- Menor consumo de energía: La NPU puede procesar modelos con un consumo de energía mucho menor que el núcleo de la CPU, lo que las hace especialmente adecuadas para dispositivos edge donde el bajo consumo de energía es crucial.
- Mayor seguridad: Las NPU permiten el procesamiento de inferencias y la toma de decisiones en el dispositivo edge, minimizando la transmisión de datos a la nube y garantizando la privacidad e integridad de los datos.
Lo que se necesita para hacer realidad la IA Edge de bajo consumo es un MCU totalmente integrado y de alto rendimiento acelerado por IA que permita una capacidad de inferencia de bajo consumo y alta seguridad, con respuestas más rápidas en tiempo real.
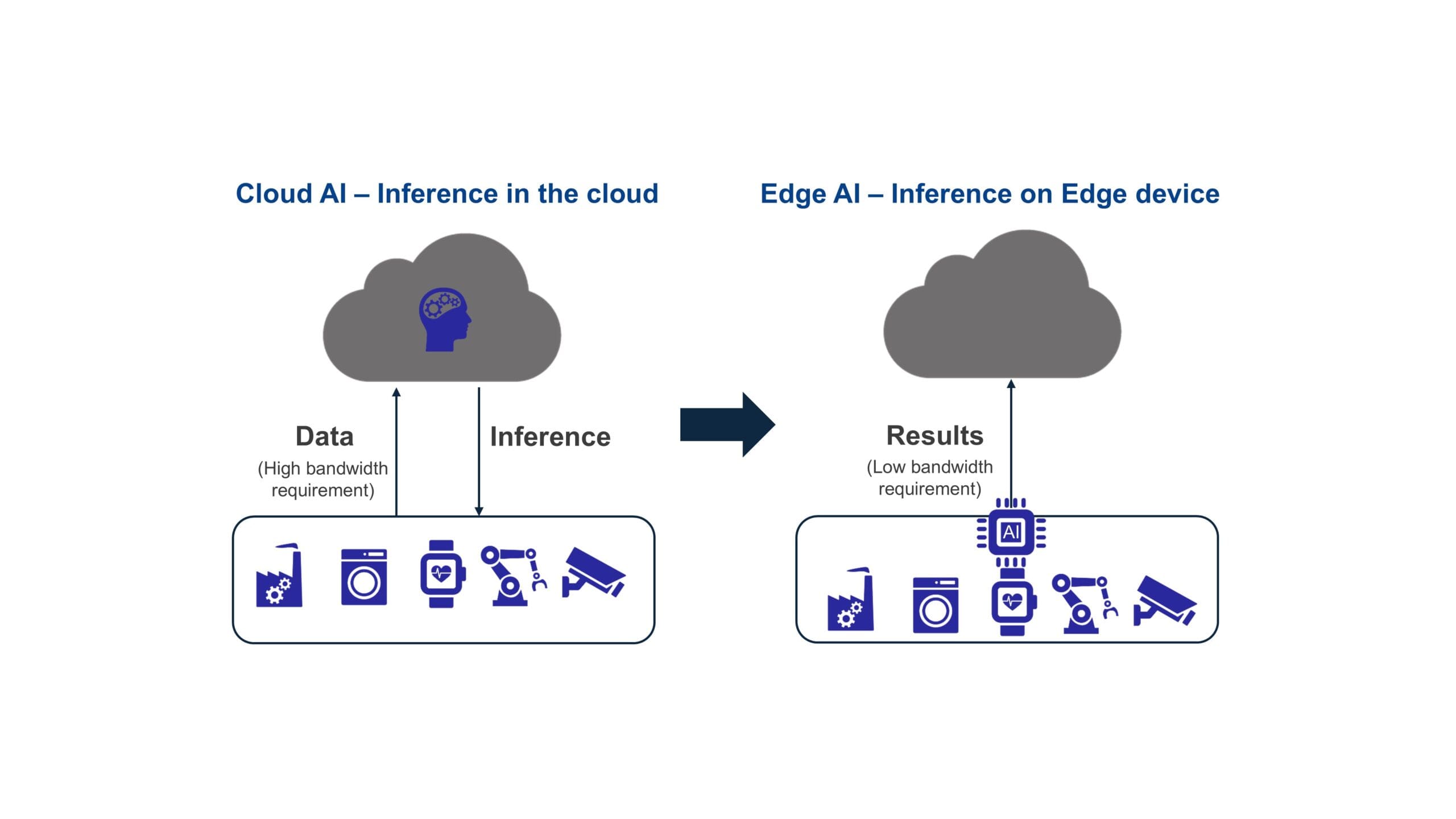
Imagen 1. Pasando de interferencia de IA en la nube a interferencia en el Edge.
Presentamos el MCU RA8P1 acelerado por IA
Los MCU RA8P1 son los primeros MCU de Renesas de uno y dos núcleos acelerados por IA. Están basados en el avanzado procesador de 22nmULL de TSMC, que combina los núcleos de CPU Arm® Cortex®-M85 (CM85) y Cortex-M33 (CM33) de máximo rendimiento con el procesador de red neuronal (NPU) Arm Ethos™-U55 para ofrecer una mejora significativa en el rendimiento de IA/ML, DSP y escalar, ideal para aplicaciones de IA Edge e IoT. Estos MCU altamente integrados ofrecen un rendimiento bruto sin precedentes de más de 7300 CoreMarks, 256 GOPS de rendimiento de IA y, junto con una gran memoria y un completo conjunto de periféricos, impulsan aplicaciones exigentes de voz, visión e IA y análisis en tiempo real, proporcionando un rendimiento de procesamiento mucho mayor que un núcleo de CPU por sí solo. Los MCU RA8P1 de doble núcleo mejoran significativamente el rendimiento de las aplicaciones de IA al permitir una mayor potencia de procesamiento, una partición eficiente de tareas entre los dos núcleos y un rendimiento en tiempo real y una eficiencia energética mejorados. Además, la seguridad avanzada, la memoria inmutable y TrustZone están integrados para permitir aplicaciones de IA verdaderamente seguras.
Mejora del rendimiento de la inferencia de IA con la NPU Ethos-U55
La NPU Arm Ethos-U55, integrada en el RA8P1, es un procesador dedicado optimizado para ejecutar operaciones clave de modelos de redes neuronales, como multiplicaciones de matrices y convoluciones, de forma más eficiente y con un menor consumo de energía que el núcleo de la CPU. La NPU está diseñada para funcionar a la perfección con núcleos Cortex-M. Descarga el núcleo de la CPU y admite todos los operadores utilizados en CNN y RNN. Admite pesos de 8 bits y activaciones de 8/16 bits, y utiliza SRAM del sistema y memoria no volátil para su funcionamiento mediante dos interfaces maestras AXI de 64 bits. Emplea compresión y descompresión de pesos para mejorar la velocidad de inferencia y reducir la necesidad de memoria. También admite el modo de respaldo: los operadores no compatibles con la NPU recurren al núcleo principal de la CPU Cortex-M, acelerado por software mediante CMSIS-NN. Ethos-U55 es compatible con los modelos de redes neuronales más comunes, como DS-CNN, ResNet, MobileNet, Inception, Wav2Letter, etc.
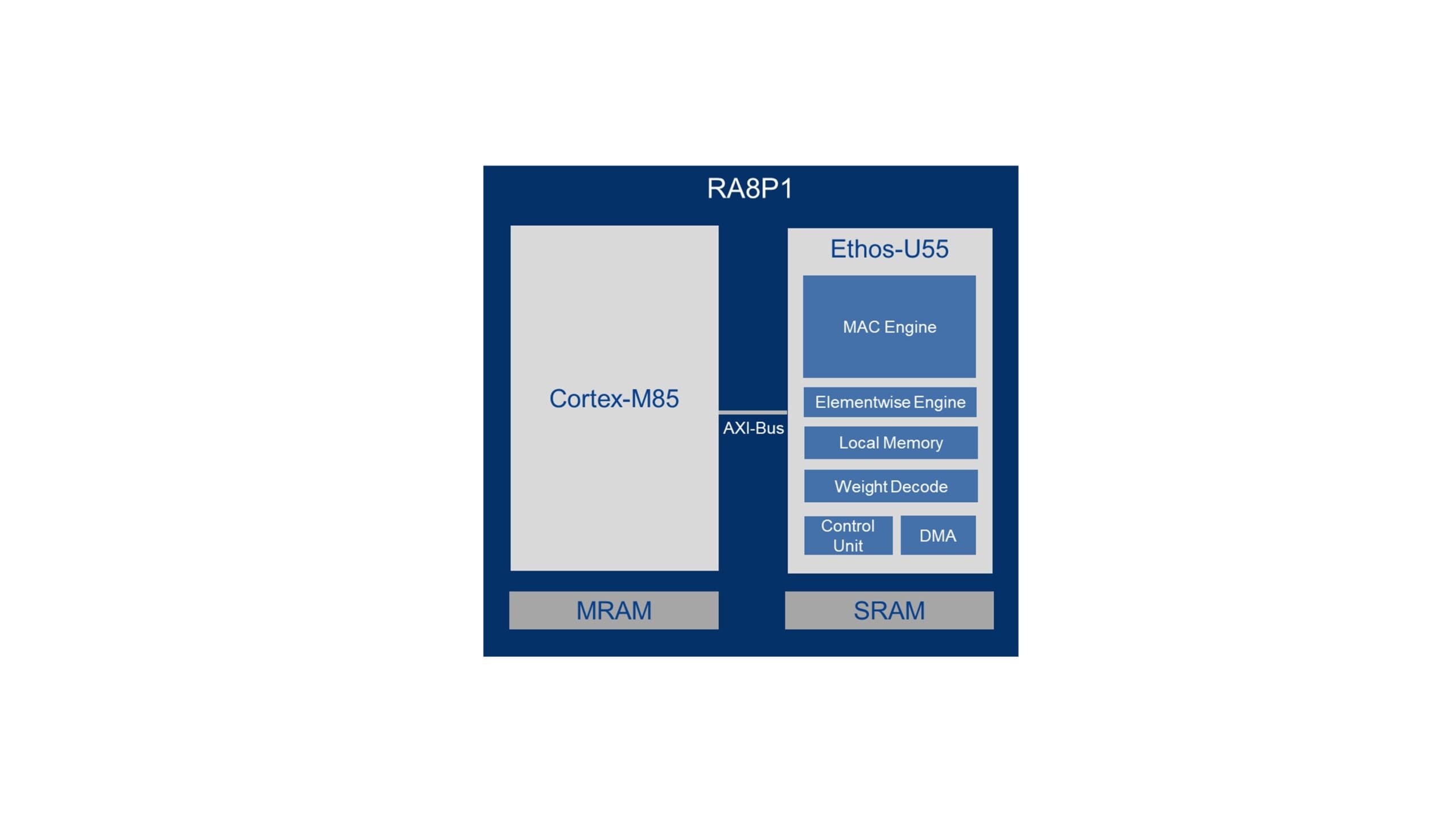
Figura 2. Arquitectura e interfaces del sistema de la NPU Ethos-U55. Fuente: Arm, Inc
Renesas ha demostrado con éxito la mejora del rendimiento de inferencia con MCU RA8P1 que utilizan Ethos-U55 para el procesamiento de inferencia. En algunos casos de uso de IA/ML, se observa una mejora significativa del rendimiento con la NPU Ethos-U55 en comparación con el núcleo de la CPU.
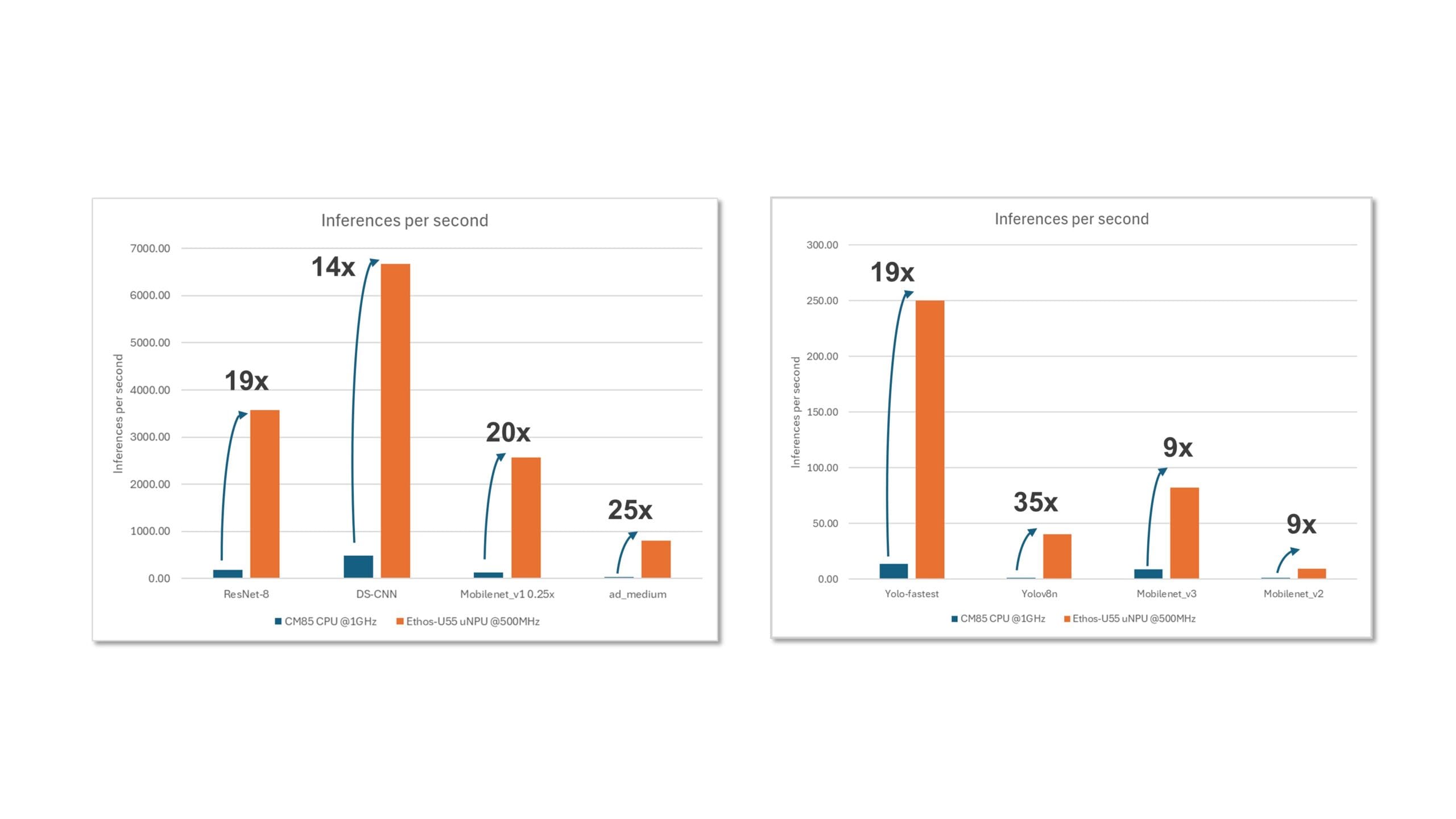
Figura 3. Mejora significativa del rendimiento de IA con la NPU Ethos-U55 en comparación con el núcleo de CPU
Modelos utilizados:
- Clasificación de imágenes: ResNet8, MobileNet v2, MobileNet v3
- Detección de palabras clave: DS-CNN
- Palabras de activación visuales: MobileNet v1
- Detección de objetos: Yolo_fastest, Yolov8N
- Detección de anomalías: ad_medium
Desarrollo de aplicaciones más rápido con el marco RUHMI
La solución de IA RA8P1 incluye el marco RUHMI, el primer entorno integral de desarrollo de IA de Renesas para MCU y MPU, integrado en el IDE e2 Studio de Renesas para optimizar e implementar modelos de redes neuronales altamente optimizados de forma independiente del marco. RUHMI permite la optimización, cuantificación y conversión de modelos a un formato compatible con MCU. Proporciona todas las herramientas, API, generador de código y entorno de ejecución necesarios para implementar un modelo preentrenado en el RA8P1. Se incluye soporte nativo para los marcos de ML comúnmente utilizados, TensorFlow Lite, Pytorch y ONNX, junto con ejemplos de aplicaciones listos para usar y modelos optimizados para RA8P1.
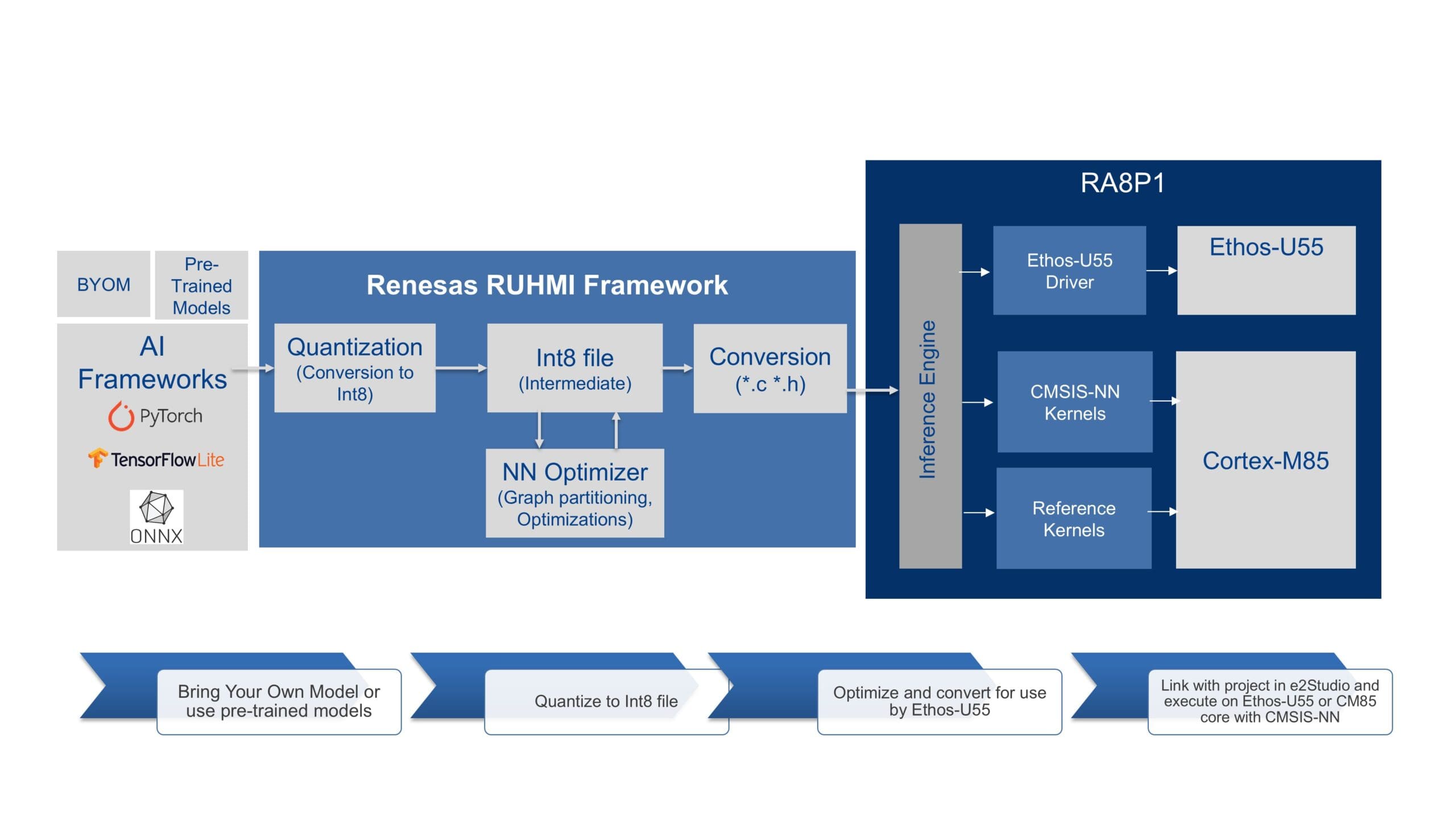
Figura 4. Flujo de trabajo de IA con el marco RUHMI de Renesas
Flujo de trabajo típico de IA con RUHMI:
- Optimización y compilación del modelo (sin conexión): Se introduce un modelo de IA preentrenado mediante marcos de trabajo comunes como Tensorflow Lite, se cuantifica a un formato intermedio Int8 y se optimiza para su ejecución en la NPU o el núcleo de la CPU. Posteriormente, el modelo se compila a un formato compatible con MCU (normalmente *.c/*.h) que la NPU puede ejecutar.
- Entrada y preprocesamiento de datos: La MCU captura los datos de entrada sin procesar (imagen de una cámara, audio de un micrófono). La CPU preprocesa estos datos para escalarlos y formatearlos para su entrada al modelo de IA.
- Ejecución en la NPU: El núcleo de la CPU envía los datos de entrada preprocesados y el flujo de comandos del modelo de IA compilado a la NPU para su ejecución. La NPU lee el flujo de comandos y, utilizando los datos de entrada y los pesos del modelo (normalmente almacenados en la memoria local), procesa cada capa de la red neuronal, pasando los resultados intermedios a las capas adyacentes.
- Salida y posprocesamiento: Una vez que la NPU ha procesado todas las capas de la red neuronal, envía los resultados de la inferencia (p. ej., las coordenadas y la clasificación del cuadro delimitador del objeto o una señal de «palabra de activación detectada») a la CPU principal, que puede realizar cualquier posprocesamiento y acción necesarios (p. ej., superponer cuadros delimitadores en una imagen, activar una acción o enviar datos a la nube).
Aplicaciones de IA habilitadas por RA8P1
Gracias a su alto rendimiento de inferencia, bajo consumo de energía y capacidad de procesamiento en tiempo real, el RA8P1 es ideal para una amplia gama de aplicaciones de IA en diversos segmentos del mercado, como:
- IA de voz: Detección de palabras clave, reconocimiento de voz, reconocimiento de habla, identificación de oradores
- IA de visión: Detección de objetos, clasificación de imágenes, reconocimiento de gestos, reconocimiento facial, análisis de imágenes, monitoreo de conductores/vehículos
- Análisis en tiempo real: Detección de anomalías, análisis de vibraciones, mantenimiento predictivo
- Aplicaciones multimodales: HMI inteligente con capacidad de voz y visión, cámaras de vigilancia mejoradas, robótica con entradas visuales y auditivas para la detección e interacción con el entorno
En la siguiente sección, veremos dos ejemplos de implementaciones de IA en RA8P1.
Ejemplo de aplicación 1: Clasificación de imágenes en RA8P1
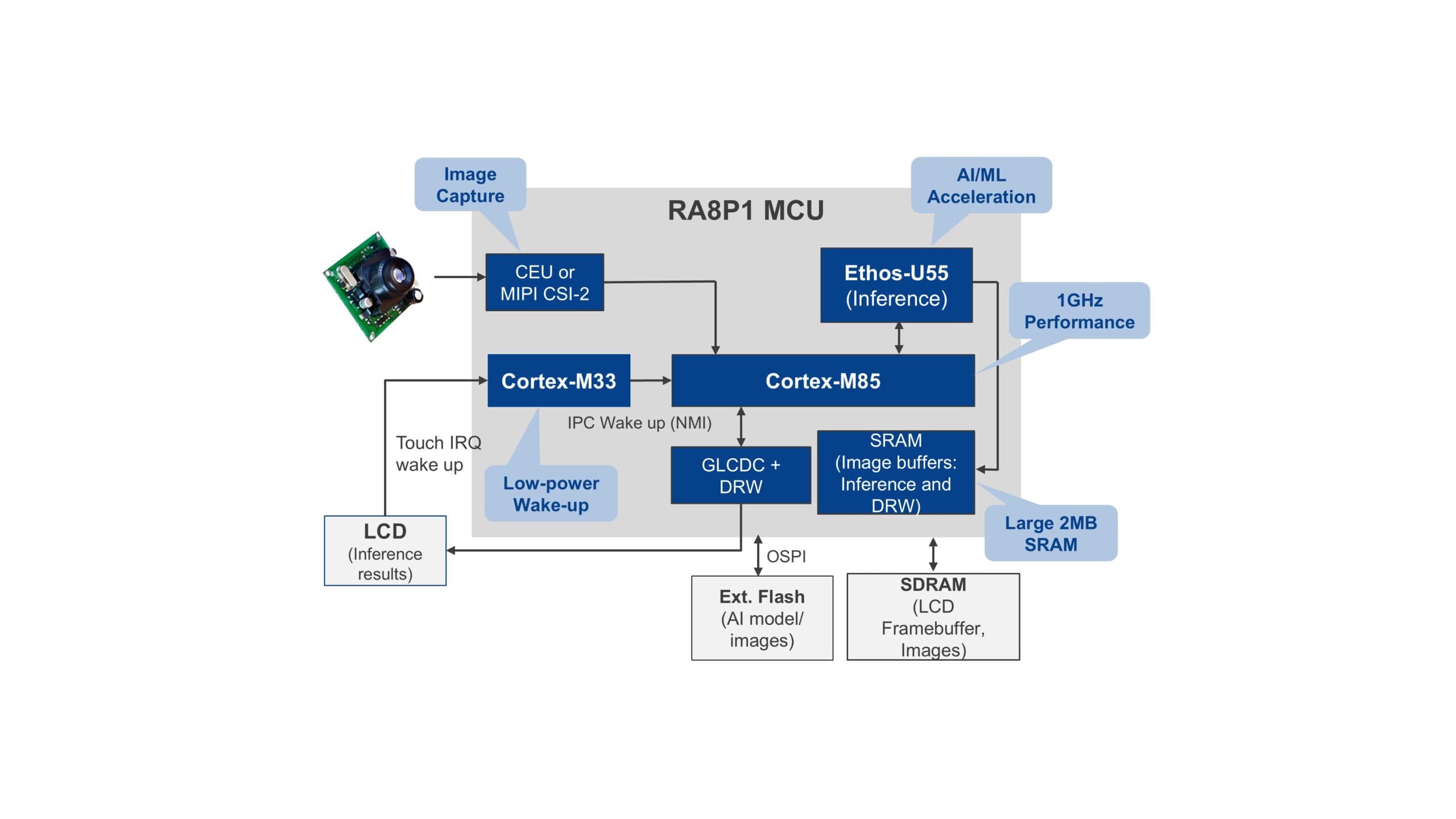
Figura 5. Diagrama de bloques del sistema de clasificación de imágenes
La Figura 5 muestra una aplicación de IA de clasificación de imágenes que analiza una imagen de entrada y le asigna una etiqueta o categoría preasignada. El modelo de red neuronal se entrena iterativamente con un amplio conjunto de datos de imágenes etiquetadas, hasta que la precisión de predicción del modelo alcanza un nivel muy alto. Este modelo preentrenado puede implementarse en el MCU RA8P1. Para la inferencia, se introduce una nueva imagen de entrada en el modelo y se recorre a través de las capas de la red entrenada. La capa de salida proporciona la distribución probabilística de todas las categorías, y la categoría con la mayor probabilidad se asigna como etiqueta de la imagen. Estos datos de salida (etiqueta y precisión de la imagen) pueden enviarse a la pantalla o a la nube.
En nuestra implementación, observamos una mejora de 33 veces en la velocidad de inferencia con el Ethos-U55 en comparación con el uso del núcleo de la CPU, y un consumo de energía de 62 mA ejecutando inferencias a 1000 fps (incluyendo accesos a memoria externa).

Figura 6. Clasificación de imágenes en RA8P1 y comparación de rendimiento, NPU vs. CPU
La clasificación de imágenes se puede utilizar en diversas aplicaciones:
- Seguridad: identificación de armas, reconocimiento de personas, detección de anomalías
- Comercio minorista: creación de catálogos de productos por categoría, gestión de inventario
- Agricultura: identificación de enfermedades en cultivos, clasificación de plantas
- Ciudades inteligentes: identificación de semáforos/señales y peatones
- Electrodomésticos inteligentes: identificación de objetos dentro de refrigeradores
Ejemplo de aplicación 2: Sistema de monitoreo de conductores en RA8P1
Esta aplicación muestra el Sistema de Monitoreo de Conductores (SDM) Nota-ai, una solución de seguridad en cabina que mejora la seguridad vial en todos los aspectos de los viajes en vehículo. El SDM Nota-ai ejecuta múltiples modelos para detectar conductores no registrados, somnolencia, uso del teléfono celular y distracciones como fumar. Con el RA8P1, observamos un aumento de 4 a 24 veces en el rendimiento de inferencia para los cuatro modelos utilizados en esta aplicación: detección facial, puntos de referencia facial, puntos de referencia ocular y detección de teléfono. El consumo de corriente promedio medido con los cuatro modelos en funcionamiento fue de 86 mA.
El DMS se utiliza en cámaras de salpicadero, grabadoras de datos de vehículos y sistemas de monitorización del conductor.
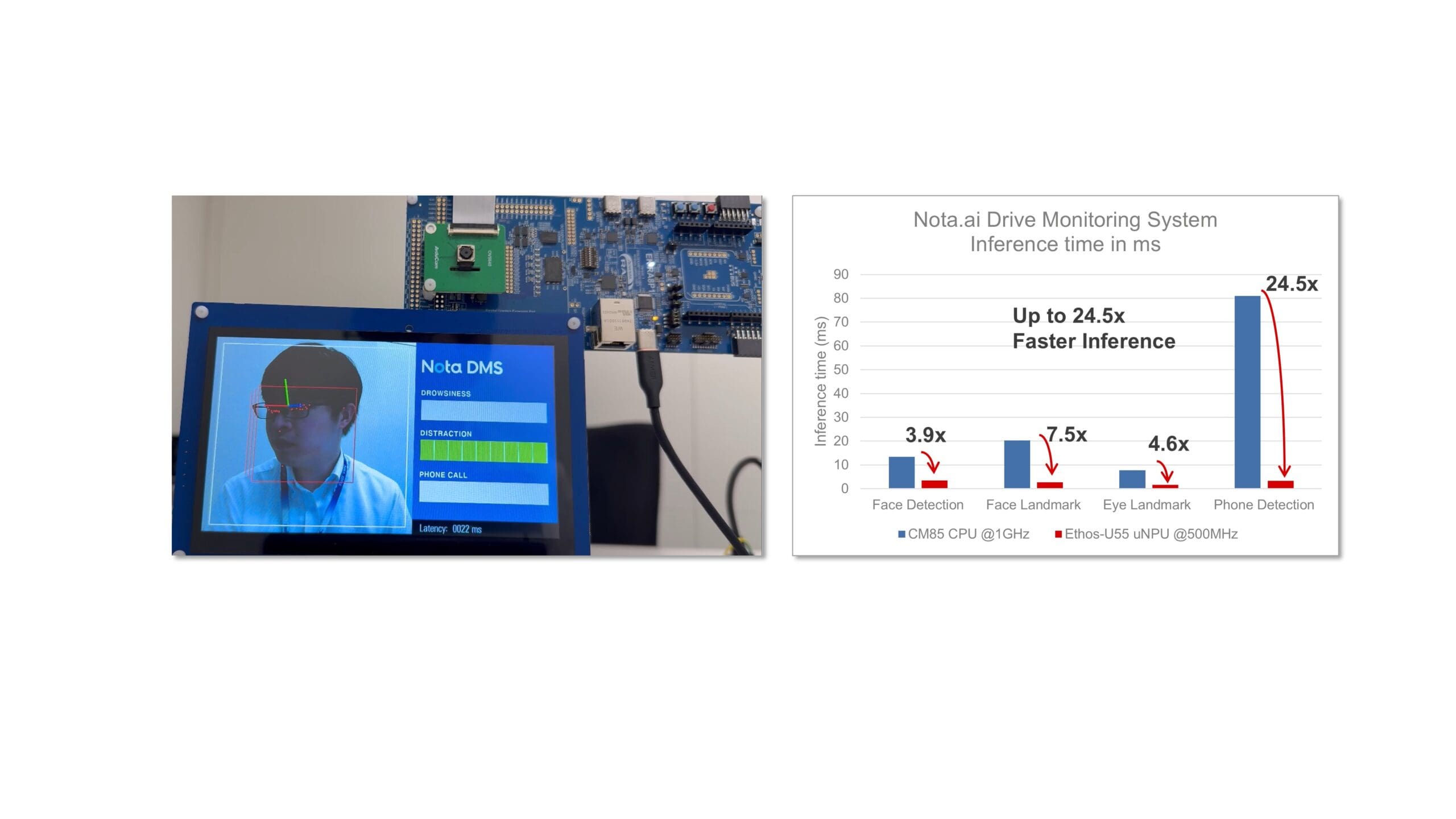
Figura 7. Sistema de Monitoreo de Controladores en RA8P1 y Comparación de Rendimiento, NPU vs. CPU
Ambas aplicaciones de IA de Visión optimizan el uso de los recursos del MCU RA8P1
- Adquisición eficiente de imágenes de entrada a través del sensor de imagen:
- El RA8P1 incluye una interfaz MIPI CSI-2 con una unidad de escalado de imágenes o la interfaz de cámara paralela CEU de 16 bits para capturar datos de entrada de imágenes sin procesar.
- Procesamiento de inferencia de alto rendimiento con la NPU Ethos-U55:
- El acelerador de IA Ethos-U55 recibe imágenes procesadas de la interfaz de cámara MIPI CSI-2 o CEU y procesa modelos de IA complejos de forma más eficiente y con menor consumo de energía que el núcleo de la CPU.
- Procesamiento de aplicaciones más rápido con núcleos de CPU Arm Cortex-M85 y Cortex-M33:
- El núcleo CM85 de alto rendimiento de 1 GHz con extensiones vectoriales Arm Helium se utiliza para el preprocesamiento y posprocesamiento de los datos de entrada y los resultados de la inferencia. Los operadores no compatibles con el Ethos-U55 pueden ser ejecutados por el núcleo CM85 en modo de respaldo. Con el procesamiento de inferencia descargado a la NPU, la CPU CM85 puede utilizarse por completo para código de aplicación de alto rendimiento.
- El núcleo Cortex-M33 de 250 MHz en los MCU RA8P1 de doble núcleo puede utilizarse para tareas de activación y mantenimiento de bajo consumo.
- Almacenamiento eficiente de imágenes, pesos de modelos y activaciones con memoria integrada e interfaces de memoria
- La memoria MRAM de 1 MB y la memoria SRAM de 2 MB integradas son cruciales para almacenar pesos de modelos de IA, imágenes y resultados intermedios.
- Las interfaces de memoria externa de alto rendimiento (OSPI con XIP y descifrado sobre la marcha, y SDRAM de 32 bits) pueden utilizarse para modelos más grandes.
- Periféricos gráficos avanzados para procesamiento gráfico e HMI
- El controlador LCD gráfico (con interfaces paralelas o MIPI DSI) y el motor gráfico 2D pueden utilizarse para renderizar imágenes y resultados de inferencia en la pantalla LCD.
- Opciones de conectividad flexibles:
- Existen diversas opciones de conectividad para transmitir resultados de inferencia, imágenes o alertas/notificaciones, ya sea a dispositivos locales o a la nube, para su almacenamiento o análisis.
Conclusión
Las aplicaciones de IA de borde se benefician enormemente del uso de MCU acelerados por IA. Estos facilitan aplicaciones donde el rendimiento en tiempo real, el bajo consumo y la seguridad son aspectos cruciales. La incorporación de la NPU a los MCU de bajo consumo ha supuesto un cambio transformador en el panorama de las soluciones de IA. Los nuevos MCU RA8P1 reducen drásticamente la latencia, permiten la privacidad de los datos y minimizan el consumo de energía, lo que los hace ideales para aplicaciones alimentadas por batería. Todo el desarrollo está respaldado por el completo marco RUHMI de Renesas, que ayuda a los desarrolladores a optimizar e implementar sus modelos de IA de forma eficiente en el hardware RA8P1.
Para más información, visite www.renesas.com/ra8p1



: lo que significa para el Edge Computing")

