
En los últimos años, ha habido una explosión en la cantidad de dispositivos IoT conectados en mercados tan diversos como la automatización industrial, hogares inteligentes, automatización de edificios y dispositivos portátiles. Estos dispositivos conectados, o «cosas», comparten un rasgo común: todos se comunican entre sí y comparten datos generados por múltiples sensores. Un nuevo pronóstico de International Data Corporation estima que habrá 41,6 mil millones de dispositivos IoT conectados, o «cosas», que generarán 79,4 zettabytes (ZB) de datos en 2025.
A medida que aumenta la cantidad de dispositivos conectados, también lo hace la cantidad de datos que se generan. Estos datos se pueden recopilar y, en muchos casos, analizar y utilizar para tomar decisiones sobre los propios dispositivos sin necesidad de conectividad a la nube. Esta capacidad de analizar datos, extraer conocimientos de ellos y tomar decisiones autónomas basadas en el análisis, es la esencia de la Inteligencia Artificial (IA). Una combinación de IA e IoT, o Inteligencia Artificial de las Cosas (AIoT), permite la creación de dispositivos «inteligentes» que aprenden de los datos y toman decisiones autónomas sin intervención humana. Esto lleva a que los productos tengan interacciones más lógicas y similares a las humanas con su entorno.
Hay varios factores que impulsan esta tendencia para generar inteligencia en los dispositivos de borde: una mayor toma de decisiones en el borde reduce la latencia y los costos asociados con la conectividad en la nube y hace posible la operación en tiempo real. La falta de ancho de banda a la nube es otra razón para trasladar la computación y la toma de decisiones al dispositivo “on the Edge”. La seguridad también es una consideración: los requisitos de privacidad y confidencialidad de los datos impulsan la necesidad de procesar y almacenar datos en el dispositivo.
La combinación de IA e IoT ha abierto nuevos mercados para MCU. Ha permitido un número cada vez mayor de nuevas aplicaciones y casos de uso que pueden usar MCU simples emparejados con aceleración de IA para facilitar el control inteligente. Estas MCU habilitadas con IA brindan una combinación única de capacidad DSP para computación y aprendizaje automático (ML) para inferencia y ahora se utilizan en aplicaciones tan diversas como detección de palabras clave, fusión de sensores, análisis de vibraciones y reconocimiento de voz. Las MCU de mayor rendimiento permiten aplicaciones más complejas en visión e imágenes, como reconocimiento facial, análisis de huellas dactilares y robots autónomos.
Tecnologías de IA
Como hemos visto, la IA es la tecnología que permite que los dispositivos de IoT aprendan de entradas anteriores, tomen decisiones y ajusten sus respuestas en función de nuevas entradas, todo sin la intervención de los humanos. A continuación, se muestran algunas tecnologías que permiten la inteligencia artificial en dispositivos de IoT:
Aprendizaje automático (ML): los algoritmos de aprendizaje automático crean modelos basados en datos representativos, lo que permite a los dispositivos identificar patrones automáticamente sin intervención humana. Los proveedores de ML proporcionan algoritmos, API y herramientas necesarias para entrenar modelos que luego pueden fusionarse en sistemas integrados. Estos sistemas integrados luego utilizan los modelos previamente entrenados para impulsar inferencias o predicciones basadas en nuevos datos de entrada. Ejemplos de aplicaciones son concentradores de sensores, detección de palabras clave, mantenimiento predictivo y clasificación.
Aprendizaje profundo (Deep Learning): el aprendizaje profundo es una clase de aprendizaje automático que entrena un sistema mediante el uso de muchas capas de una red neuronal para extraer progresivamente características e información de alto nivel a partir de datos de entrada complejos. El aprendizaje profundo trabaja con datos de entrada muy grandes, diversos y complejos y permite que los sistemas aprendan de manera iterativa, mejorando el resultado con cada paso. Ejemplos de aplicaciones que utilizan el aprendizaje profundo son el procesamiento de imágenes, los chatbots para servicio al cliente y el reconocimiento facial.
Procesamiento del lenguaje natural (NLP): NLP es una rama de la inteligencia artificial que se ocupa de la interacción entre sistemas y humanos utilizando el lenguaje natural. La PNL ayuda a los sistemas a comprender e interpretar el lenguaje humano (texto o habla) y a tomar decisiones basadas en eso. Algunos ejemplos de aplicaciones son los sistemas de reconocimiento de voz, la traducción automática y la escritura predictiva.
Visión por ordenador: la visión por ordenador / máquina es un campo de inteligencia artificial que entrena a las máquinas para recopilar, interpretar y comprender datos de imágenes y tomar medidas en función de esos datos. Las máquinas recopilan imágenes / videos digitales de las cámaras, utilizan modelos de aprendizaje profundo y herramientas de análisis de imágenes para identificar y clasificar objetos con precisión y tomar medidas en función de lo que «ven». Algunos ejemplos son la detección de fallas en la línea de ensamblaje de fabricación, los diagnósticos médicos, el reconocimiento facial en las tiendas minoristas y las pruebas de automóviles sin conductor.
AIoT en MCU
En el pasado, la inteligencia artificial era el ámbito de las MPU y las GPU con potentes núcleos de CPU, grandes recursos de memoria y conectividad en la nube para análisis. Sin embargo, en los últimos años, con una tendencia hacia una mayor inteligencia “on the Edge”, estamos comenzando a ver que las MCU se utilizan en aplicaciones AIoT integradas. El movimiento hacia el edge está siendo impulsado por consideraciones de latencia y costo e implica mover el cálculo más cerca de los datos. La IA en dispositivos IoT basados en MCU permite la toma de decisiones en tiempo real y una respuesta más rápida a los eventos, y tiene las ventajas de menores requisitos de ancho de banda, menor consumo de energía, menor latencia, menores costos y mayor seguridad. AIoT está habilitado por una mayor capacidad de cómputo de las MCU recientes, así como la disponibilidad de marcos de redes neuronales delgadas (NN) que son más adecuados para las MCU con recursos limitados que se utilizan en estos dispositivos finales.
Una red neuronal es una colección de nodos, dispuestos en capas que reciben entradas de una capa anterior y generan una salida que se calcula a partir de una suma ponderada y sesgada de las entradas. Esta salida se pasa a la siguiente capa a lo largo de todas sus conexiones salientes. Durante el entrenamiento, los datos de entrenamiento se introducen en la primera capa o la capa de entrada de la red, y la salida de cada capa se pasa a la siguiente. La última capa o capa de salida produce las predicciones del modelo, que se comparan con los valores esperados conocidos para evaluar el error del modelo. El proceso de entrenamiento implica refinar o ajustar los pesos y sesgos de cada capa de la red en cada iteración mediante un proceso llamado retropropagación, hasta que la salida de la red se correlacione estrechamente con los valores esperados. En otras palabras, la red «aprende» iterativamente del conjunto de datos de entrada y mejora progresivamente la precisión de la predicción de salida.
El entrenamiento de la red neuronal requiere un rendimiento informático y una memoria muy altos y, por lo general, se lleva a cabo en la nube. Después del entrenamiento, este modelo NN previamente entrenado se integra en la MCU y se utiliza como motor de inferencia para nuevos datos entrantes basados en su entrenamiento.
Esta generación de inferencia requiere un rendimiento informático mucho menor que el entrenamiento del modelo y, por lo tanto, es adecuada para una MCU. Los pesos de este modelo NN preentrenado son fijos y se pueden colocar en flash, reduciendo así la cantidad de SRAM requerida y haciéndolo adecuado para MCU con más recursos limitados.
Implementación en MCU
La implementación de AIoT en MCU implica algunos pasos. El enfoque más común es utilizar uno de los modelos de marco de red neuronal (NN) disponibles como Caffe o Tensorflow Lite, adecuado para soluciones de dispositivos finales basadas en MCU. El entrenamiento del modelo NN para el aprendizaje automático se realiza en la nube por especialistas en inteligencia artificial que utilizan herramientas proporcionadas por los proveedores de inteligencia artificial. La optimización del modelo NN y la integración en la MCU se lleva a cabo utilizando herramientas del proveedor de AI y del fabricante de MCU. La inferencia se realiza en la MCU utilizando el modelo NN previamente entrenado.
El primer paso del proceso se realiza completamente fuera de línea e implica la captura de una gran cantidad de datos del dispositivo final o la aplicación, que luego se utiliza para entrenar el modelo NN. El desarrollador de IA define la topología del modelo para hacer un mejor uso de los datos disponibles y proporcionar la salida que se requiere para esa aplicación. El entrenamiento del modelo NN se realiza pasando los conjuntos de datos de forma iterativa a través del modelo con el objetivo de minimizar continuamente el error en la salida del modelo. Hay herramientas disponibles con el marco NN que pueden ayudar en este proceso.
En el segundo paso, estos modelos previamente entrenados, optimizados para ciertas funciones como la detección de palabras clave o el reconocimiento de voz, se convierten a un formato adecuado para MCU. El primer paso en este proceso es convertirlo en un archivo de búfer plano utilizando la herramienta de conversión AI. Opcionalmente, esto se puede ejecutar a través del cuantificador, para reducir el tamaño y optimizarlo para la MCU. Este archivo de búfer plano se convierte luego en código C y se transfiere a la MCU de destino como un archivo ejecutable en tiempo de ejecución.
Esta MCU, equipada con el modelo de IA integrado previamente entrenado, ahora se puede implementar en el dispositivo final. Cuando ingresan nuevos datos, se ejecutan a través del modelo y se genera una inferencia basada en el entrenamiento. Cuando ingresan nuevas clases de datos, el modelo NN se puede enviar de vuelta a la nube para volver a entrenar y el nuevo modelo reentrenar se puede programar en la MCU, potencialmente a través de actualizaciones de firmware OTA.
Hay dos formas diferentes de diseñar una solución de IA basada en MCU. Para el propósito de esta discusión, asumimos el uso de núcleos Arm Cortex-M en las MCU objetivo.
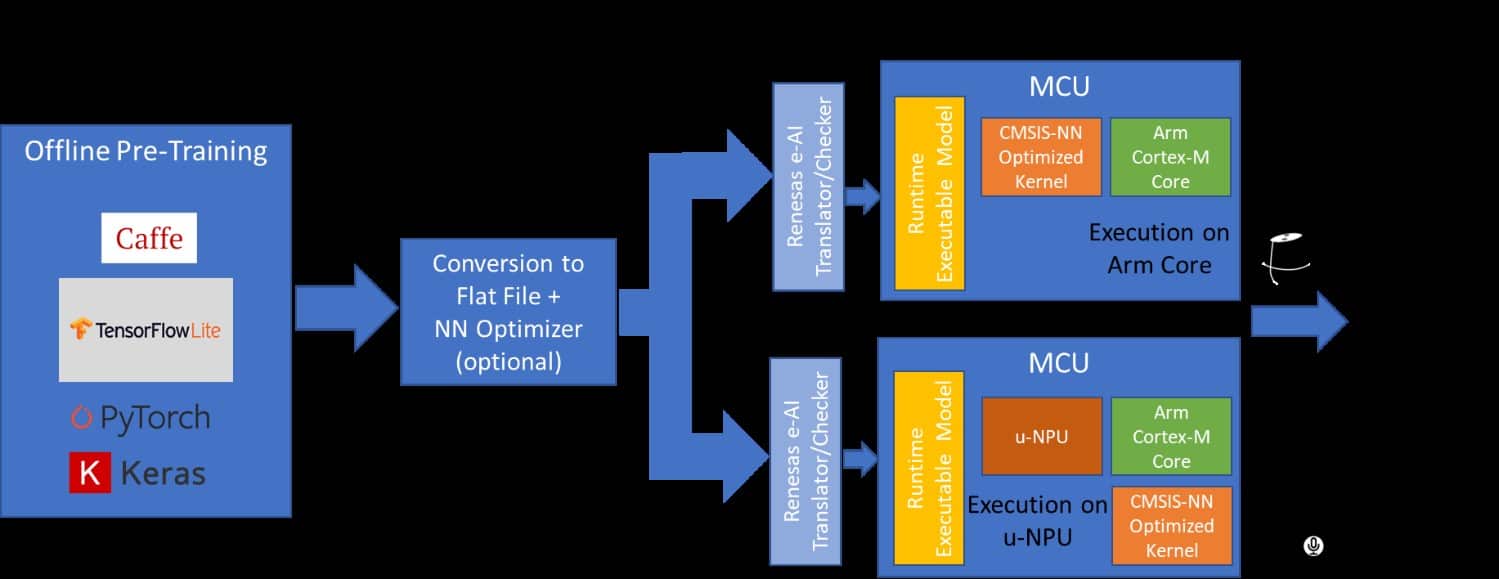
En el primer método, el modelo NN convertido se ejecuta en el núcleo de la CPU Cortex-M y se acelera utilizando las bibliotecas CMSIS-NN. Esta es una configuración simple que se puede manejar sin ninguna aceleración de hardware adicional y es adecuada para las aplicaciones de IA más simples, como la detección de palabras clave, el análisis de vibraciones y los concentradores de sensores.
Una opción más sofisticada y de mayor rendimiento implica incluir un acelerador NN o hardware de unidad de procesamiento micro neural (u-NPU) en la MCU. Estas u-NPU aceleran el aprendizaje automático en dispositivos finales de IoT con recursos limitados y pueden admitir una compresión que puede reducir la potencia y el tamaño del modelo. Son compatibles con los operadores que pueden ejecutar completamente la mayoría de las redes NN comunes para el procesamiento de audio, el reconocimiento de voz, la clasificación de imágenes y la detección de objetos. Las redes que no son compatibles con la u-NPU pueden volver al núcleo de la CPU principal y son aceleradas por las bibliotecas CMSIS-NN. En este método, el modelo NN se ejecuta en la uNPU.
Estos métodos muestran solo un par de formas de incorporar IA en dispositivos basados en MCU. A medida que las MCU empujan los límites de rendimiento a niveles más altos, más cercanos a los esperados de las MPU, esperamos comenzar a ver capacidades de IA completas, incluidos algoritmos de aprendizaje e inferencia livianos, que se construyen directamente en las MCU.
Renesas y AI
Renesas tiene una familia completa de MCU basados en Arm, la familia RA, que son capaces de ejecutar aplicaciones de inteligencia artificial. Todas las MCU de la familia RA son compatibles con los núcleos Arm Cortex-M y un rico conjunto de funciones que incluye Flash en chip y SRAM y periféricos de comunicación en serie, Ethernet, gráficos / HMI y funciones analógicas. También admiten seguridad avanzada con criptografía simétrica y asimétrica, almacenamiento inmutable, aislamiento de activos de seguridad y resistencia a la manipulación.
Renesas está trabajando en estrecha colaboración con socios del ecosistema para brindar soluciones de inteligencia artificial de extremo a extremo en análisis predictivo, aplicaciones de visión y voz, entre otras. Estas nuevas tecnologías AIoT han abierto nuevas oportunidades importantes para las MCU de Renesas. Las aplicaciones que utilizan estas capacidades abarcan segmentos del mercado como la automatización industrial, hogares inteligentes, automatización de edificios, atención médica y agricultura.
La solución «e-AI» (IA integrada) de Renesas utiliza los dos modelos populares de NN, Caffe, desarrollado por UC Berkeley y TensorFlow de Google. Utiliza Deep Neural Network (DNN), una red de múltiples capas, que es particularmente adecuada para aplicaciones que involucran clasificación de imágenes, reconocimiento de voz o procesamiento de lenguaje natural.
Las herramientas e-AI de Renesas integradas en el entorno de desarrollo integrado de e2 Studio convierten el modelo NN en un formulario (basado en C / C ++) que puede utilizar la MCU y ayudan a incrustar el modelo NN previamente entrenado en la MCU de destino. Esta MCU habilitada para IA ahora se puede implementar en dispositivos finales de IoT.
AI “on the Edge” es el futuro
La implementación de IA en MCU con recursos limitados aumentará exponencialmente en el futuro y seguiremos viendo nuevas aplicaciones y casos de uso que surjan a medida que las MCU superen los límites del rendimiento y difuminen la línea entre MCU y MPU, y cada vez más modelos NN «delgados»., adecuados para dispositivos con recursos limitados, estén disponibles. En el futuro, con un aumento en el rendimiento de la MCU, es probable que veamos la implementación de algoritmos de aprendizaje ligeros además de la inferencia, que se ejecutan directamente en la MCU. Esto abrirá nuevos mercados y aplicaciones para los fabricantes de MCU y se convertirá en un área de inversión significativa para ellos.
")



")